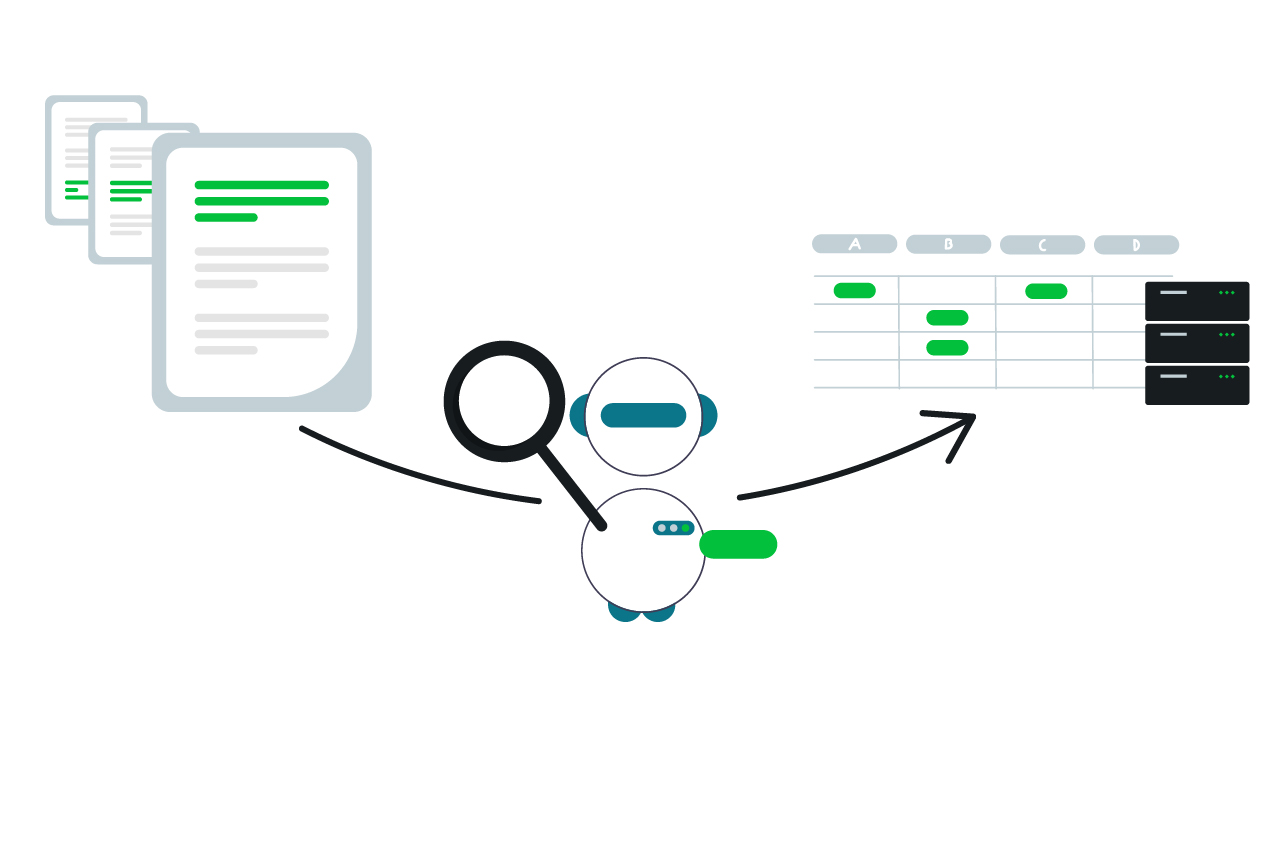
Die Aufgabe
Geschäftsberichte folgen in Deutschland keinem einheitlichen Format; jedes Unternehmen entscheidet selbst über Inhalt und Form der Veröffentlichung. Was für das Unternehmen angenehm ist, wird zum Problem für jemanden, der viele Berichte automatisiert analysieren will, um Kennzahlen zu extrahieren (wie unsere Partner bei North Data). Als Beispiel hier einige Passagen aus drei Geschäftsberichten, in denen die Anzahl der beschäftigten Mitarbeiter genannt ist:
- „Das Unternehmen beschäftigt zum Stichtag 31. Dezember 2021 insgesamt 75 Arbeitnehmer (VJ 73 Arbeitnehmer).“
- „Die Arbeitnehmerschaft umfasst zum Bilanzstichtag 211 Mitarbeiter, darunter 83 kfm. Angestellte mit z.T. qualifizierter, produktspezifischer Fachausbildung, 80 gewerbliche Arbeitnehmer, …“
- „Belegte Plätze zum Stichtag 31.12.2021: Werkstatt Gaißach: 145, Werkstatt Polling: 149 …, Gesamt: 603, …“
Die Vielzahl von möglichen Formulierungen erschwert die Analyse mit klassischen Mitteln – oft ist eine komplizierte Logik aus Schlagwortsuchen mit Synonymentabellen notwendig, um robust die richtigen Werte zu extrahieren, sofern das überhaupt möglich ist.
Sprachmodelle brauchen keine Schlagworte
LLMs wie OpenAIs GPT-Modelle besitzen die neuartige Fähigkeit, natürliche Sprache zu „verstehen“. Sie können semantische Zusammenhänge im Text modellieren und sind nicht von spezifischen Formulierungen oder Formatierungen abhängig. Einen Text mit GPT-3.5 (ChatGPT) zu analysieren, ist prinzipiell einfach: Man übergibt den zu analysierenden Text inklusive einer Anweisung in natürlicher Sprache an die OpenAI-API.
Dafür verpacken wir den Geschäftsbericht und unsere fachliche Frage (etwa: „Wie viele Mitarbeiter sind im Unternehmen angestellt?“) in ein sogenanntes Prompt, eine präzise Anweisung für das LLM, wie es unsere Anfrage bearbeiten und wie es antworten soll. Die genaue Formulierung des Prompts kann die Qualität der Ergebnisse stark beeinflussen; Prompt Engineering ist mittlerweile zu einer eigenen Wissenschaft geworden.
„You are a financial auditor answering questions about a financial report.
You are given excerpts from a financial report as context to consider for your answer.
You only use information from the context to answer the question.
If you cannot answer a question, you simply state that you cannot answer it.
Your answers are as concise and to the point as possible. You answer in {output_language}.“
---
Context: {context}
---
Question: {query}
Prompt für GPT-3.5 mit Platzhaltern für Kontext und Frage
Mit dem passenden Prompt liefert ChatGPT uns die gesuchte Information – so weit die Theorie. In der Praxis sind aber wie immer einige Hürden zu überwinden, um von einem interessanten Beispiel zu einer nützlichen Anwendung zu kommen.
Problem 1: Kontextlänge
LLMs sind begrenzt in der Größe des Textes, den sie verarbeiten können – die bekannten Modelle von OpenAI, GPT-3.5-Turbo und GPT-4, haben ein sogenanntes Kontextfenster von 16.000 Tokens (~5.400 Wörter in deutscher Sprache), welche sie maximal auf einmal verarbeiten können. Das ist genug, um kürzere Texte in Gänze zu erfassen, reicht aber bei Weitem nicht für Geschäftsberichte großer Unternehmen, die oft hunderte Seiten umfassen können. Außerdem kosten lange Texte bares Geld: Die Abrechnung der API-Nutzung erfolgt pro Token in der Anfrage. Grund genug also, eine Vorauswahl von relevanten Textabschnitten zu treffen, anstatt den gesamten Bericht zu OpenAI zu senden. Doch wie entscheiden wir, welche Textabschnitte für unsere Frage relevant sind, ohne diese analysiert zu haben? Dies geschieht mit semantischen Embeddings.
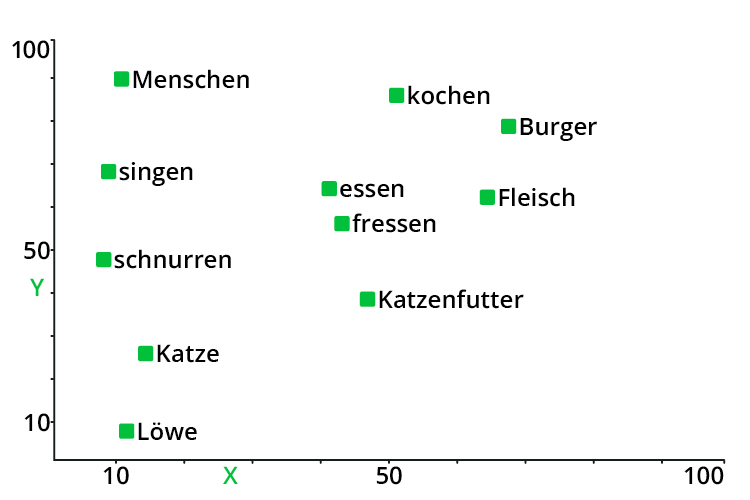
Embeddings sind ein zentrales Element in der Verarbeitung natürlicher Sprache – eine gute Einführung gibt es bei Cohere. Hier nur die Kurzfassung: Mithilfe von Embedding-Modellen wie Googles BERT oder OpenAIs ada-002 kann die Bedeutung von Worten und Sätzen in vektorisierter Form dargestellt werden. Dabei sind zwei Textabschnitte, die thematisch miteinander verwandt sind, im Vektorraum nah beieinander.
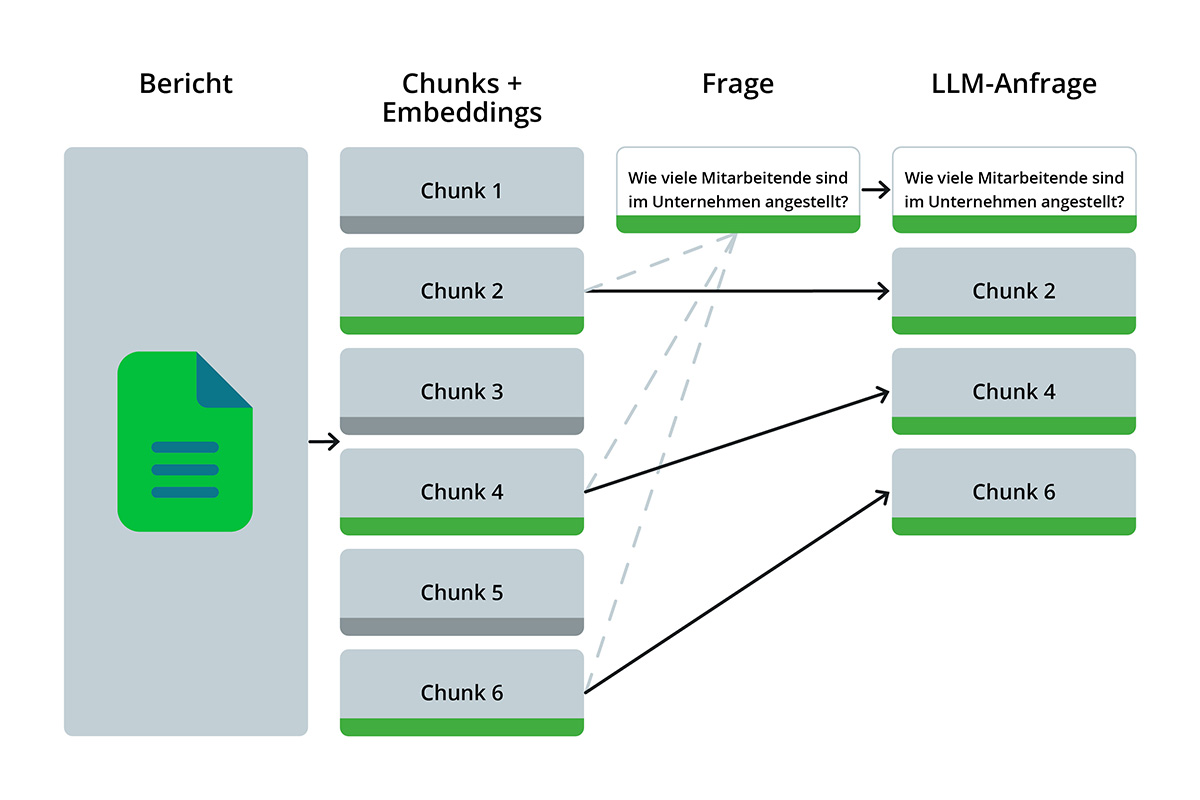
Vektordatenbanken wie Weaviate bieten einfache Schnittstellen zum Erstellen und Speichern von Embeddings, und implementieren Vektorsuchverfahren, mit denen wir Textabschnitte finden können, die thematisch ähnlich zu der von uns gestellten Frage sind. Diese können wir dann selektiv an das LLM übergeben.
Problem 2: Variable Ausgabe
Wer einmal versucht hat, Chat-GPT dazu zu bringen, nur mit einer Zahl zu antworten, weiß, dass das erstaunlich schwierig sein kann. Selbst bei expliziter gegenteiliger Anweisung liefern LLMs oft Füllwörter oder erklärende Sätze zusammen mit dem gewünschten Wert. In unserem Fall konnten wir beobachten, dass das Modell in seinen Antworten häufig Formulierungen aus dem jeweiligen Bericht imitiert:
- „Der Gewinn beträgt 1.949.948,26 Euro“
- „Der Konzernjahresüberschuss beträgt 1.900 T€.“
Aus diesen Sätzen müssen die Daten in ein einheitliches Format überführt werden. In manchen Fällen, wie im zweiten Beispiel oben, sind außerdem zusätzliche Umrechnungsschritte nötig. OpenAI nimmt uns hier mit dem function calling feature einiges an Arbeit ab – die 0631-Varianten der GPT-Modelle haben die Fähigkeit, in formatiertem JSON zu antworten. Wir könnten nun GPT-3.5 nach der Textanalyse direkt mit einem function call antworten lassen – in der Praxis haben wir aber bessere Erfahrungen damit gemacht, das Parsing in eine separate Anfrage zu verpacken und dafür das stärkere GPT-4 zu benutzen. Mit einem entsprechenden Prompt können wir so in einer Anfrage 30-50 Antwortsätze in ein definiertes Format überführen.
{
„125707201002“: „Der Gewinn oder jährliche Fehlbetrag im Bericht beträgt 4.800.893,83 EUR.“,
„11890730641033“: „Der Konzernjahresüberschuss beträgt 1.900 T €.“,
„1239576012365“: „Der Jahresüberschuss beträgt 1.998.310,31 € (2020: 11.132 €).“,
„1232545013206“: „Der Jahresüberschuss beträgt 1.997.610,50 EUR.“,
„113265703380“: „Der Jahresüberschuss beträgt 1.996.403,34 Euro.“,
…
}
Input für das Parsing mit GPT-4
{
„125707201002“: 4800893.83,
„11890730641033“: 1900000,
„1239576012365“: 1998310.31,
„1232545013206“: 1997610.5,
„113265703380“: 1996403.34,
…
}
JSON-Antwort von GPT-4 mit extrahierten Werten
Das Ergebnis
Eine Tabelle sagt mehr als tausend Worte, deshalb hier eine Evaluation der extrahierten Werte für 100 Geschäftsberichte und fünf verschiedene Fragestellungen:
| Zielgröße | Score |
|---|---|
| Geschäftsjahr | 99 % |
| Name des Wirtschaftsprüfers | 98 % |
| Anzahl Mitarbeiter | 95 % |
| Bilanzsumme | 90 % |
| Gewinn (oder Verlust) | 89 % |
Die Scores sind hier der Vergleich zu den von North Data mit klassischen Methoden extrahierten Werten. Wie man sieht, stimmen die beiden Methoden in den meisten Fällen überein! Es muss an dieser Stelle außerdem gesagt werden, dass die LLM-basierte Extraktion preislich noch nicht konkurrenzfähig ist (Stand Juli 2023). Der größte Nutzen dieses Ansatzes wird also bei Fragestellungen und Datensätzen zu finden sein, die mit klassischen Methoden nicht zugänglich sind.
Hinweis: Im zweiten Teil aus dem Juni 2025 zeigen wir im Detail, wie wir mit Google Gemini eine Lösung in Produktion gebracht haben.
