Willkommen zurück zu unserer Serie über die Analyse von Geschäftsberichten mit KI! Im ersten Teil haben wir anhand eines Beispiels gezeigt, wie die Extraktion von Kennzahlen aus Geschäftsberichten mit LLMs wie ChatGPT grundsätzlich funktioniert. Jetzt gehen wir weiter in die Tiefe und zeigen dafür eine Lösung, die wir in Zusammenarbeit mit North Data produktiv einsetzen.
Wir konnten damals demonstrieren, wie sich relevante Informationen aus den dichten Textwüsten von Geschäftsberichten strukturiert herausfiltern lassen. Doch wer das in der Praxis skalieren will, stößt schnell an Grenzen – sei es bei der Genauigkeit über viele verschiedene Dokumente hinweg, der robusten Verarbeitung komplexer Layouts und Tabellen oder der Wirtschaftlichkeit, die für eine großflächige Analyse nötig ist.
Genau hier hat sich in der Zwischenzeit aber einiges getan. Mit Gemini Flash von Google steht ein Modell bereit, das die Karten für die automatisierte Dokumentenanalyse in Sachen Geschwindigkeit, Kontextverständnis und dem Ausliefern strukturierter Daten neu mischt.1 In diesem zweiten Teil wollen wir daher tief eintauchen: Was macht Gemini Flash so viel leistungsfähiger für diese spezifische Aufgabe als frühere Ansätze oder die klassischen OCR-Pipelines? Wie ermöglicht es den Schritt von der Machbarkeitsstudie zum produktiven Werkzeug? Werfen wir einen Blick unter die Haube.

Der klassische Ansatz: OCR als Basis, aber nicht die ganze Lösung
Bevor wir uns den Fähigkeiten von Gemini widmen, lohnt sich ein kurzer Blick auf den traditionellen Weg zur Datenextraktion aus PDFs. Dieser beginnt fast immer mit Optical Character Recognition (OCR). OCR-Tools helfen uns, wenn es darum geht, Text aus gescannten Dokumenten oder reinen Bild-PDFs lesbar zu machen. Sie wandeln Pixel in Buchstaben um. Das Ergebnis ist nicht nur der „rohe“ Textinhalt, sondern oft auch dessen Position auf der Seite, meist in Form von Koordinaten oder sogenannten Bounding Boxes für jedes erkannte Wort oder jede Zeile.
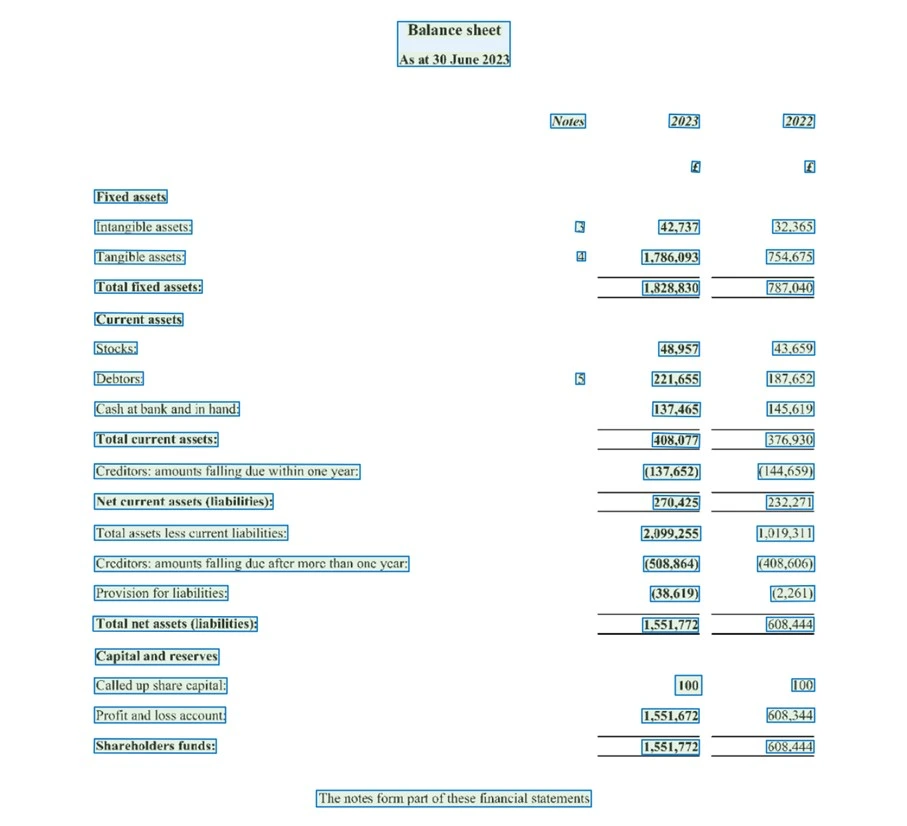
Nach diesem rohen Text samt Koordinaten fängt die eigentliche Arbeit oft erst an, denn für eine sinnvolle Analyse brauchen wir strukturierte Daten, keinen Fließtext. Hier beginnen die Herausforderungen:
Zuerst muss die Struktur im reinen Text-Output erkannt werden. Wie identifiziert man automatisch Tabellen, zusammengehörige Key-Value-Paare (wie „Umsatz: 10 Mio. €“) oder semantisch sinnvolle Blöcke? Dafür sind häufig komplexe, nachgelagerte Schritte notwendig – seien es speziell entwickelte Parser, regelbasierte Systeme, die auf bestimmte Muster achten, oder sogar separate Machine-Learning-Modelle, die auf Aufgaben wie Tabellenerkennung trainiert wurden.
Diese nachgelagerten Systeme sind allerdings oft anfällig für Layout-Änderungen. Kleine Anpassungen im Design eines Berichts von einem Jahr zum nächsten, oder die unterschiedlichen Formate verschiedener Unternehmen, können mühsam erstellte Regeln oder Parser aus dem Tritt bringen und unbrauchbar machen.
Hinzu kommt das fehlende Kontextverständnis. OCR liefert zwar den Text, versteht aber dessen Bedeutung nicht. Zu erkennen, dass sich der Begriff „Total Assets“ auf Seite 10 auf dieselbe Kennzahl bezieht wie eine detaillierte Aufschlüsselung in einer Tabelle auf Seite 45, übersteigt die Fähigkeiten reiner Texterkennung.
All diese Faktoren führen zu Komplexität und somit zu einem hohen Entwicklungs- und Wartungsaufwand. Es lässt sich feststellen: OCR ist ein wichtiges Werkzeug im Kasten. Aber für das Ziel der End-to-End-Extraktion strukturierter Daten ist es meist nur der erste Schritt in einer komplexen und oft fragilen Verarbeitungskette.
Unser Weg zum Produktiveinsatz: Evaluation, Modellwahl und Integration
Der Sprung von einer erfolgreichen Demonstration (wie in Teil 1 gezeigt2) zu einem zuverlässigen, skalierbaren Produktivsystem erforderte einen systematischen Ansatz und Weiterentwicklungen in mehreren Bereichen.
Zunächst war eine solide Evaluation unerlässlich. Wir haben also manuell einen Datensatz aus 100 repräsentativen englischen Geschäftsberichten kuratiert. Für die wichtigsten Kennzahlen wurden die korrekten Werte (Ground Truth) von Hand annotiert und in einer Tabelle gesammelt. Nur mit einer solchen verlässlichen Basis lässt sich die Qualität verschiedener Modelle und Ansätze objektiv messen und über die Zeit verfolgen.
Parallel dazu erweiterten wir den Umfang der Extraktion im Vergleich zur alten Lösung deutlich. Statt nur einiger weniger Kennzahlen war das Ziel nun, eine breite Palette von über 20 relevanten Werten pro Bericht zuverlässig zu extrahieren. Dazu gehören unter anderem die vom Unternehmen ausgewiesenen Lohnkosten, Angaben zu Gewinn und Verlust, Barmittel, aber auch Daten wie die durchschnittliche Mitarbeiterzahl oder der Name des Wirtschaftsprüfers.
Diese anspruchsvolleren Ziele führten uns zu Tests verschiedener Modelle. Die Wahl fiel schließlich auf Gemini 2.0 Flash Lite: Dieses Modell vereinte für unseren Anwendungsfall alle entscheidenden Faktoren optimal.
Qualität & Geschwindigkeit: In unseren Tests zeigte Gemini 2.0 Flash Lite eine überraschend hohe Genauigkeit für die meisten der anvisierten Kennzahlen, die oft mit der von größeren, teureren Modellen mithalten konnte. Google selbst positioniert die Flash-Modelle als optimiert für Aufgaben, bei denen es auf hohe Geschwindigkeit und Effizienz bei gleichzeitig guter Qualität ankommt3. Unsere Erfahrungen bestätigen, dass das Modell seinem „Flash“ im Namen in puncto Verarbeitungsgeschwindigkeit gerecht wird.
Kosten: Ein entscheidender Faktor für den Einsatz im großen Maßstab sind die Kosten. Gemini 2.0 Flash Lite ist deutlich günstiger als die größeren Pro-Modelle. Im Vergleich zu älteren Modellen wie gpt-3.5-turbo-16k aus dem ersten Teil, das im Juli 2023 noch etwa 3 US-Dollar pro Million Input-Token kostete4, ist die von uns genutzte Gemini-Flash-Variante um den Faktor 40 günstiger5! Das macht die Verarbeitung tausender Berichte wirtschaftlich tragbar.
Multimodalität & Kontext: Ein wesentlicher Vorteil gegenüber reinen Textmodellen oder klassischen OCR-Pipelines ist die Multimodalität von Gemini. Vereinfacht gesagt bedeutet das: Statt nur den rohen Text und dessen Koordinaten zu liefern (wie traditionelle OCR), kann Gemini Flash gleichzeitig den Text „lesen“ und das Seitenlayout „sehen“. Es „versteht“, wie Text in Spalten oder Tabellen angeordnet ist, erkennt Überschriften und kann Bilder oder Diagramme im Dokument interpretieren. Dadurch erfasst es den Kontext, den die reine Textreihenfolge oft nicht vermittelt, wesentlich besser. Dies ist gerade bei den komplexen und variantenreichen Layouts von Geschäftsberichten ein großer Vorteil. Gepaart mit dem langen Kontextfenster, das die Analyse umfangreicher Dokumentabschnitte am Stück erlaubt, ist dies ein entscheidender Fortschritt.
Diese Kombination aus guter Qualität, hoher Geschwindigkeit, niedrigen Kosten und der Fähigkeit, Dokumente ganzheitlich zu verstehen, machte Gemini 2.0 Flash Lite zur guten Wahl für unseren produktiven Einsatz in Zusammenarbeit mit North Data.
Gemini Flash in Aktion: Der Workflow mit Structured Outputs
Der Kern unseres Ansatzes kombiniert die Stärken von Gemini mit pragmatischen Lösungen, um auch mit den Eigenheiten sehr umfangreicher Dokumente umzugehen.
Ein zentrales Problem stellen lange Geschäftsberichte dar, die oft hunderte von Seiten umfassen. Das gesamte Dokument an Gemini zu übergeben, wäre zwar ideal für den Kontext, ist aber zu teuer für den Masseneinsatz. Um dieses Problem zu umgehen, haben wir einen mehrstufigen Ansatz entwickelt: Zuerst setzen wir nach wie vor auf bewährte OCR-Technologie, um den reinen Text des gesamten Dokuments zu extrahieren. Dieser Rohtext dient uns dann als Basis für eine schnelle Voranalyse mittels Schlüsselwörtern. Wir suchen nach Begriffen und Phrasen, die typischerweise auf relevante Abschnitte hindeuten, wie zum Beispiel „Consolidated Balance Sheet“, „Income Statement“ oder „Notes to the Financial Statements“.
Basierend auf dieser Analyse wählen wir die bis zu 100 Seiten aus, die am wahrscheinlichsten die gesuchten Finanzkennzahlen enthalten. Nur dieser Auszug des Berichts wird dann als PDF-Kontext an Gemini Flash Lite übergeben. Dieser Kniff reduziert nicht nur die Verarbeitungskosten erheblich, sondern hilft auch, das Modell auf die wirklich wichtigen Teile des Dokuments zu konzentrieren und das „Rauschen“ irrelevanter Seiten zu minimieren.
Nachdem wir die relevanten Seiten isoliert haben, beauftragen wir Gemini mit der gezielten Extraktion in ein vordefiniertes Format. Ein weiterer Baustein für präzise Ergebnisse ist hierbei die Nutzung von sogenannten Structured Outputs. Gemini besitzt die Fähigkeit, nicht nur Text zu generieren, sondern direkt strukturierte JSON-Daten zu liefern, die einem vorgegebenen Schema folgen.
Wir definieren dazu im Vorfeld ein klares Zielschema, das genau festlegt, welche Datenfelder wir erwarten und in welchem Format (wie etwa „Zahl“, „Text“, „Währungssymbol“). In Python nutzen wir dafür gerne Pydantic zur einfachen Definition und Validierung. Diese Struktur geben wir dem Modell explizit als Anweisung mit. Das ist nicht nur praktisch für die automatisierte Weiterverarbeitung, sondern verbessert auch nachweislich die Qualität: In unseren Tests führte allein dieser Schritt zu einer Verbesserung des Evaluations-Ergebnisses um rund 4 %.
Hier ein vereinfachtes Python-Beispiel zur Illustration des Prinzips mit der google-genai -Bibliothek und Structured Outputs:
from google import genai
from google.genai import types
from pydantic import BaseModel, Field
client = genai.Client(api_key="GEMINI_API_KEY")
# Define the desired output structure using Pydantic
class FinancialData(BaseModel):
revenue: float | None = Field(
description="Total revenue reported for the fiscal year."
)
net_income: float | None = Field(description="Net income or profit after tax.")
total_assets: float | None = Field(description="Total assets value.")
fiscal_year: int | None = Field(description="The ending year of the fiscal period.")
currency_symbol: str | None = Field(
description="Currency symbol used for major values (e.g., $, £, €)."
)
# Upload the relevant PDF pages (assuming 'selected_report_pages.pdf' was created by pre-filtering)
pdf_file = client.files.upload(file="'selected_report_pages.pdf")
prompt = """
Please analyze the provided pages from the annual report PDF.
Extract the following financial figures for the main consolidated entity reported:
- Total Revenue
- Net Income (Profit after tax)
- Total Assets
- The Fiscal Year End
- The primary Currency Symbol used for the main financial figures (£, $, € etc.)
Return the data strictly adhering to the provided 'FinancialData' schema.
If a value cannot be found or determined confidently, leave the corresponding field null.
Pay close attention to units (e.g., thousands, millions).
"""
try:
response = client.models.generate_content(
model="gemini-2.0-flash-lite-001",
contents=[prompt, pdf_file],
config=types.GenerateContentConfig(
response_mime_type="application/json",
response_schema=FinancialData,
),
)
extracted_data = FinancialData.model_validate_json(response.text)
print(extracted_data)
except Exception as e:
print(f"\nAn error occurred: {e}")
finally:
client.files.delete(name=pdf_file.name)
Ein Blick auf die Zahlen: Wie gut funktioniert es wirklich?
Um die tatsächliche Leistung unseres Ansatzes mit Gemini Flash objektiv zu bewerten, haben wir, wie erwähnt, einen Datensatz aus 100 manuell annotierten Geschäftsberichten erstellt. Dieser dient als Ground Truth, gegen den wir die Extraktionsergebnisse des Modells prüfen.
Die Gesamtgenauigkeit über alle Kennzahlen und Berichte hinweg für unseren Ansatz lag bei 83,5 %. Dies waren die ersten Machbarkeitswerte für die Lösung, die wir bei North Data integriert haben. Das ist eine solide Basis und zeigt, dass der Ansatz grundsätzlich funktioniert. Interessanter wird es jedoch, wenn man sich die Genauigkeit für einzelne Kennzahlen ansieht:
| Kennzahlen (Parameter) | Genauigkeit |
|---|---|
| Gesamt (Overall) | 83.5% |
| capital | 96.0% |
| cash | 95.0% |
| employees | 95.0% |
| revenue | 95.0% |
| equity | 98.0% |
| currencySymbol | 99.0% |
| auditorName | 89.0% |
| materials | 89.0% |
| … | … |
| liabilities (creditors) | 75.0% |
| currentAssets | 64.0% |
| realEstate | 60.0% |
| receivables | 52.0% |
| tax | 41.0% |
Was verrät uns diese Tabelle und wo liegen die aktuellen Hürden?
Die Evaluationsergebnisse zeichnen ein klares Bild: Bei klar definierten Stammdaten oder Werten, die in Geschäftsberichten oft prominent und relativ einheitlich ausgewiesen werden, erzielt das Modell sehr hohe Genauigkeitswerte. Dazu zählen beispielsweise capital (Eigenkapital), equity (Reinvermögen), die employees (Anzahl der Mitarbeiter), cash (Barmittel) oder das currencySymbol (Währungssymbol). Erfreulicherweise sind Halluzinationen – also das Erfinden von Zahlen, die im Dokument nicht existieren – in unseren Tests kein signifikantes Problem gewesen. Wenn Fehler auftraten, dann meist durch Fehlinterpretationen vorhandener Zahlen, nicht durch deren freie Erfindung.
Schwieriger wird es für das Modell bei komplexeren Kennzahlen. Hier zeigen sich die Grenzen des aktuellen Ansatzes, insbesondere wenn es um semantische Unschärfe und variierende Detailgrade geht. Viele Bilanzposten können in Berichten unterschiedlich definiert, benannt oder aufgeschlüsselt sein. Begriffe wie „Total Assets“ sind nicht immer absolut eindeutig – meint es die Bilanzsumme vor oder nach Abzug bestimmter Posten wie Goodwill, also den immateriellen Firmenwert?
Die genaue Abgrenzung von currentAssets (kurzfristige Vermögenswerte), receivables (Forderungen) oder liabilities (Verbindlichkeiten) variiert zwischen Unternehmen und Berichtsstandards. Hier stößt das Modell manchmal an seine Grenzen, die exakte, im jeweiligen Bericht gültige Definition allein aus dem unmittelbaren Kontext zu erschließen.
Ebenso spielt die Abhängigkeit von Layouts und der Platzierung von Informationen eine Rolle. Einige Werte, wie beispielsweise realEstate (Immobilienvermögen), sind oft nicht prominent auf den Hauptseiten der Bilanz zu finden, sondern detailliert in den „Notes to the Financial Statements“ (Anhang) versteckt. Die Fähigkeit des Modells, solche Informationen über verschiedene Seiten und Layouts hinweg korrekt zuzuordnen, ist stark gefordert und führt zu niedrigeren Genauigkeitswerten.
Schließlich erfordern manche Kennzahlen komplexere Interpretationen oder implizite Berechnungen. Die Extraktion von Werten wie tax (Steuern) ist hierfür ein gutes Beispiel. Oft spielen verschiedene Steuerarten (Ertragssteuern, Umsatzsteuern etc.) und latente Steuern eine Rolle, die über mehrere Abschnitte verteilt sein können. Die korrekte Zusammenführung und Interpretation dieser Informationen sind anspruchsvoll, was die aktuelle Genauigkeit von nur 41 % für diese Kennzahl erklärt.
Diese quantitativen Ergebnisse bestätigen unsere qualitativen Beobachtungen: Das Modell ist hervorragend darin, klar benannte Informationen zu finden. Bei Mehrdeutigkeiten, stark variierenden oder komplexen Layouts und der Notwendigkeit, implizites Wissen oder Zusammenhänge über mehrere Textstellen hinweg zu verstehen, stößt es jedoch an Grenzen.
Ein weiterer wichtiger Aspekt ist die variierende Genauigkeit zwischen verschiedenen Unternehmen. Die Standardabweichung der Genauigkeit pro Unternehmen liegt bei etwa 9,2 %. Besonders auffällig ist, dass die Genauigkeit bei den sehr großen, oft hunderte Seiten umfassenden und individuell gestalteten Berichten von börsennotierten Unternehmen (PLCs) wie AstraZeneca (50 %), Barclays (65 %), HSBC (50 %), Shell (70 %) oder Unilever (55 %) teilweise deutlich abfällt.
Tests mit unterschiedlich langen Ausschnitten aus den Berichten zeigten, dass die Länge des zu bewältigenden Kontextes für Gemini keine größere Schwierigkeit darstellt. Wir gehen daher davon aus, dass vor allem die Einzigartigkeit der Berichtsstrukturen dieser Konzerne für das Modell herausfordernd sind. Während Gemini Flash Lite gut mit Layouts zurechtkommt, die oft von kleineren Unternehmen mit Standardsoftware erstellt werden, sind diese komplexen Fälle eine größere Hürde. Eine Erklärung könnte sein, dass es die vom Standard abweichenden Berichte seltener in Geminis Trainingsdaten geschafft haben.
Ein weiteres wiederkehrendes Problem ist die korrekte Erfassung von Einheiten und Skalierungen. Das Übersehen oder die Fehlinterpretation von Angaben wie „in Tausend £“ oder „Millions USD“ führt zu extrahierten Werten, die um Faktoren von 1.000 oder 1.000.000 falsch sind. Hier sind robuste nachgelagerte Validierungsregeln und gezieltes Prompting notwendig, um das Modell für diese Details zu sensibilisieren.
Auch die Darstellung negativer Zahlen, die in Geschäftsberichten oft durch Klammern erfolgt (z.B. „(1.234)“ statt „-1.234“), erfordert einen expliziten Hinweis im Prompt, damit das Modell diese Konvention korrekt interpretiert und die Zahlen mit dem richtigen Vorzeichen extrahiert. Wie bereits gesagt stellen Halluzinationen (im Gegensatz zu älteren Modellen) hier keine großen Probleme dar, bloß die Interpretation der Zahlen gelingt nicht immer.
Zu guter Letzt stehen wir auch vor dem klassischen Trade-off zwischen Kosten und Leistung bei besonders komplexen Fällen. Anspruchsvollere Reasoning-Ansätze wie Chain-of-Thought (CoT), bei denen das Modell seine „Gedankenschritte“ explizit macht, oder der Einsatz noch größerer und leistungsfähigerer Modelle (z.B. Gemini 2.5 Pro) könnten bei den genannten Problemen, insbesondere bei den komplexen Berichten, Abhilfe schaffen.
Diese sind jedoch aktuell oft noch deutlich teurer. So ist beispielsweise Gemini 2.5 Pro derzeit 16- bis 32-mal so teuer wie das von uns genutzte Gemini 2.0 Flash Lite. Auch das sehr gängige GPT-4.1, welches in ChatGPT zum Einsatz kommt, kostet mit 2 $ pro 1 Million Input Tokens ca. 27-mal so viel wie Gemini 2.0 Flash Lite. Die Verarbeitung eines durchschnittlichen Berichts aus unserem Testdatensatz mit 30 Seiten kostet mit unserer Lösung daher nur ca. 0,0007 $!
Fazit: Gemini Flash als leistungsstarke Ergänzung im Werkzeugkasten
Gemini Flash hat sich für uns als nützlicher Baustein erwiesen, um die Extraktion strukturierter Daten aus Geschäftsberichten auf ein neues Level zu heben und in den produktiven Einsatz bei North Data zu bringen. Es ersetzt nicht zwangsläufig die gesamte klassische Pipeline (wie unsere OCR-Vorfilterung zeigt), aber es bietet eine enorm leistungsfähige, integrierte Alternative für den Kernprozess der intelligenten Datenextraktion und -strukturierung.
Die Fähigkeit, Layouts zu verstehen, über einen größeren Kontext zu arbeiten und direkt strukturierte Outputs zu liefern, reduziert die Komplexität und den Wartungsaufwand im Vergleich zu traditionellen, mehrstufigen Ansätzen erheblich. Die Herausforderungen bleiben, aber der Fortschritt ist deutlich und eröffnet neue Möglichkeiten für die automatisierte Finanzdatenanalyse.
Wir sind gespannt, wie sich diese Technologie weiterentwickelt und welche neuen Lösungsansätze sich ergeben. Habt ihr ähnliche Erfahrungen gemacht oder andere Strategien entwickelt? Teilt eure Gedanken mit uns!
Dieser Blogpost wurde mit Unterstützung von Gemini-2.5-Pro geschrieben.
-
OmniAI OCR Benchmark, abgerufen am 17.06.25 ↩
-
cronn Blog: Analyse von Geschäftsberichten mit ChatGPT – Teil 1 ↩
-
Dokumentation Google Gemini 2.0 Flash-Lite, abgerufen am 17.06.25 ↩
-
Web Archive: OpenAI-Preise vom 14. Juni 2023, abgerufen am 17.06.25 ↩
-
Preise für die Gemini Developer API, abgerufen am 17.06.25 ↩
