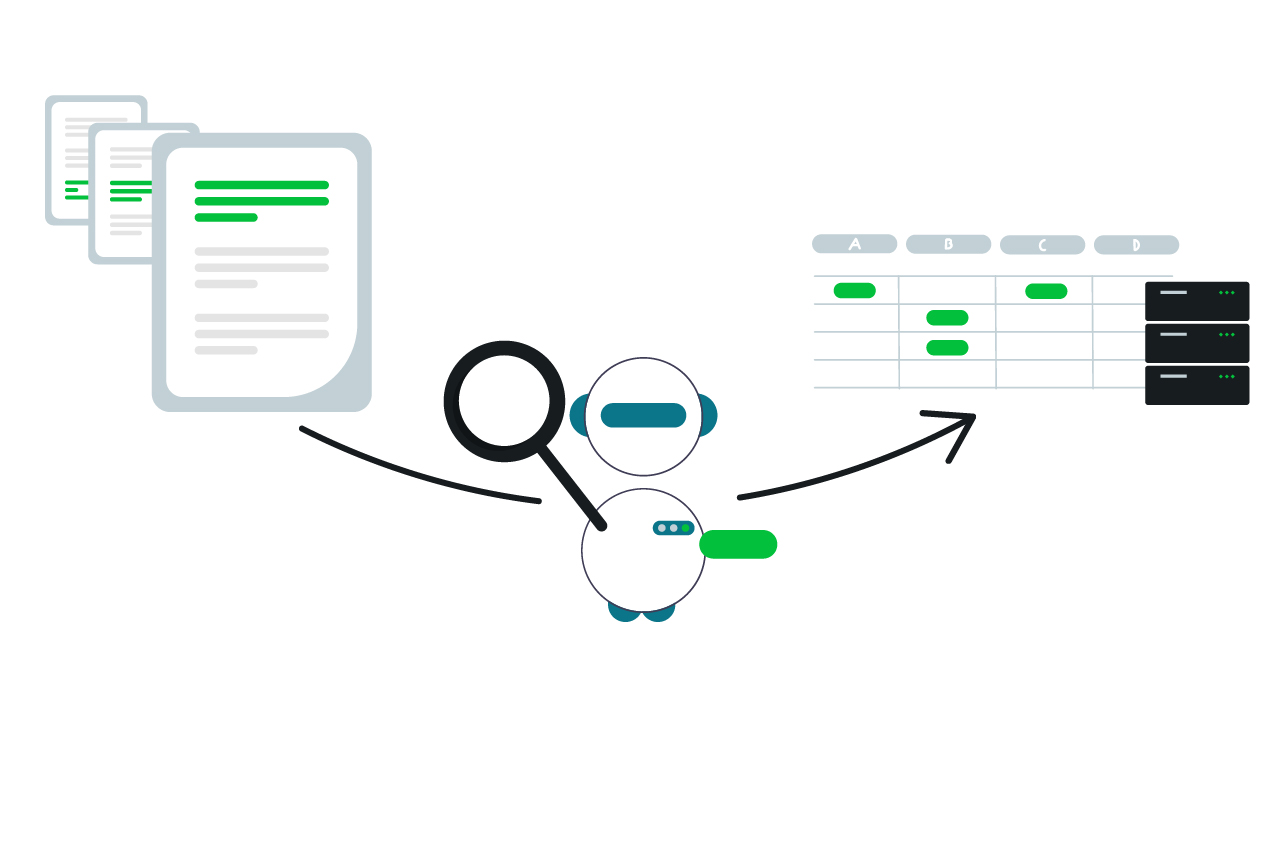
The task
In Germany, annual reports do not follow a uniform format; each company decides for itself on the content and its form of publication. This is convenient for companies, but becomes a problem for someone who wants to analyze many reports automatically in order to extract key figures (like our partners at North Data). As an example, here are some passages from three annual reports in which the number of employees is mentioned:
- “As of December 31, 2021, the company employs a total of 75 employees (previous year: 73 employees).”
- “As of the balance sheet date, the workforce comprises 211 employees, including 83 commercial employees, some of whom have qualified, product-specific specialist training, 80 industrial employees, …”
- “Occupied places as of 31.12.2021: Gaißach workshop: 145, polling workshop: 149 …, total: 603, …”
The large number of possible formulations makes any analysis by classic means difficult – keyword searches require the creation of synonym tables in order to extract the correct values, and sometimes even this is not enough to seamlessly automate the process.
Language models don’t need keywords
LLMs, such as OpenAI’s GPT models, possess the novel ability to “understand” natural language. They can model semantic relationships in the text and are not dependent on specific formulations or formatting. Analyzing a text with GPT-3.5 (ChatGPT) is easy in principle: You pass the text to be analyzed, including a natural language instruction, to the OpenAI API.
To do this, we package the annual report and our technical question (e.g.: “How many employees are employed in the company?”) in a so-called prompt, a precise instruction for the LLM on how to process our request and how to respond. The exact wording of the prompt can greatly affect the quality of the results; Prompt Engineering has now become a science in its own right.
“You are a financial auditor answering questions about a financial report.
You are given excerpts from a financial report as context to consider for your answer.
You may only use information from the context to answer the question.
If you cannot answer a question, you simply state that you cannot answer it.
Your answers are as concise and to the point as possible. You answer in {output_language}.”
---
Context: {context}
---
Question: {query}
Prompt for GPT-3.5 with placeholders for context and question
With the right prompt, ChatGPT provides us with the information we are looking for – at least in theory. In practice, however, as always, there are some hurdles to overcome in order to move from an interesting example to a useful application.
Problem 1: Context Length
LLMs are limited in the size of the text they can process – the well-known models of OpenAI, GPT-3.5-Turbo and GPT-4, have a so-called context window of 16,000 tokens (~5,400 words in German), which they can process in one go. This is enough to cover shorter texts in their entirety, but it is far from sufficient for annual reports of large companies, which can often comprise hundreds of pages. In addition, long texts cost money: The API usage is billed per token in the request. Reason enough, then, to make a pre-selection of relevant sections of text instead of sending the entire report to OpenAI. But how do we decide which sections of text are relevant to our question without having analyzed them? This is done with semantic embeddings.
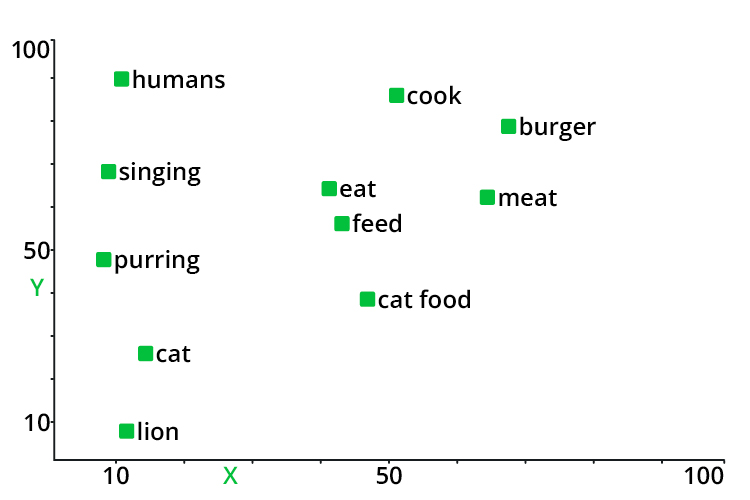
Embeddings are a central element in natural language processing – a good introduction can be found at Cohere. Here is just the short version: With the help of embedding models such as Google’s BERT or OpenAI’s ada-002, the meaning of words and sentences can be represented in vectorized form. Two sections of text that are thematically related to each other are close to each other in the vector space.
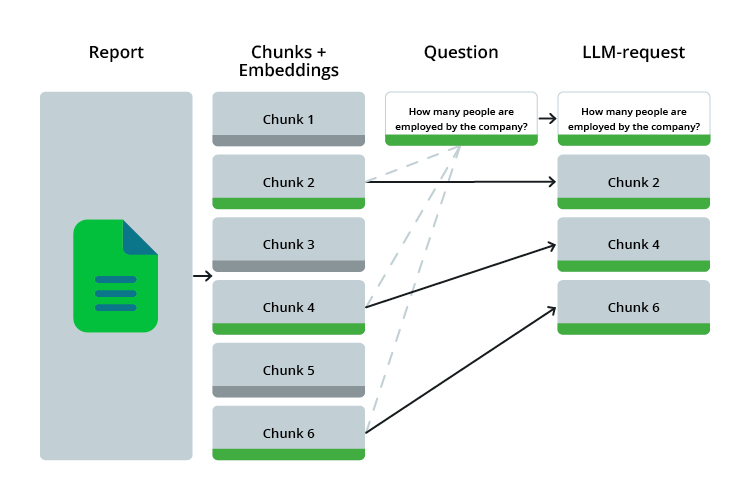
Vector databases such as Weaviate provide simple interfaces for creating and storing embeddings, and implement vector search techniques that allow us to find sections of text that are thematically similar to the question we asked. We can then selectively transfer these to the LLM.
Problem 2: Variable Output
Anyone who has ever tried to get Chat-GPT to answer with just a number knows that this can be surprisingly difficult. Even with an explicit statement to the contrary, LLMs often provide filler words or explanatory sentences along with the desired value. In our case, we observed that the model often imitates formulations from the respective report in its answers:
- “The profit is 1,949,948.26 euros”
- “Consolidated net income amounts to € 1,900 thousand.”
From these sets, the data must be converted into a uniform format. In some cases, as in the second example above, additional conversion steps are also necessary. OpenAI does a lot of work for us here with the function calling feature – the 0631 variants of the GPT models have the ability to respond in formatted JSON. We could now have GPT-3.5 respond directly with a function call after text analysis – but in practice we have had better experience with handling parsing in a separate request and using the stronger GPT-4 for this purpose. With a corresponding prompt, we can convert 30-50 response sentences into a defined format in one request.
{
“125707201002“: "The profit or annual deficit in the report is EUR 4,800,893.83.”,
“11890730641033": "Consolidated net income amounts to € 1,900 thousand.”,
“1239576012365": "Net income for the year amounts to €1,998,310.31 (2020: €11,132).”,
“1232545013206": "The net profit for the year amounts to EUR 1,997,610.50.”,
“113265703380": "The net profit for the year amounts to 1,996,403.34 euros.”,
…
}
Input for parsing with GPT-4
{
“125707201002”: 4800893.83,
“11890730641033”: 1900000,
“1239576012365”: 1998310.31,
“1232545013206”: 1997610.5,
“113265703380”: 1996403.34,
…
}
JSON response from GPT-4 with extracted values
The result
One table is worth a thousand words, so here is an evaluation of the extracted values for 100 annual reports and five different questions:
| Target | Score |
|---|---|
| Fiscal Year | 99 % |
| Name of the Auditor | 98 % |
| Number of employees | 95 % |
| Total assets | 90 % |
| Profit (or loss) | 89 % |
The scores here are the comparison to the values extracted by North Data using classical methods. As you can see, the two methods coincide in most cases! It must also be said at this point that LLM-based extraction is not (yet) competitive in terms of price. The greatest benefit of this approach will therefore be found in questions and data sets that are not accessible with classical methods.
Note: In the second part from June 2025, we show in detail how we put a solution into production with Google Gemini.
