
Rückblick
In Teil 1 haben wir gezeigt, wie wir die Hardware unseres neuen HPC-Servers eingerichtet haben. Im zweiten Teil geht es jetzt mit der Software weiter.
Installation des CUDA-Toolkits und der NVIDIA Treiber
Ubuntu stellt im non-free (restricted) Repository NVIDIA-Treiber bereit, die sich aber als veraltet herausstellen. Wir nehmen daher die aktuellen Treiber von NVIDIA:
- NVIDIA stellt ein Package-Repository für Ubuntu bereit. Die Installation ist damit ohne besonderen Aufwand möglich.
- Für CUDA stellt NVIDIA ein hohes Maß an Abwärtskompatibilität sicher. Die zu der Zeit aktuelle CUDA-Version 12.8 unterstützt die deutlich ältere GPU-Architektur „Pascal“ der Tesla P40 GPUs.
- Eine aktuelle Version von CUDA und passenden Treibern ist Voraussetzung, um mit aktuellem KI-Tooling arbeiten zu können.
Der NVIDIA-Installationsguide für das CUDA-Toolkit führt diverse Möglichkeiten und Pfade auf:
- Package Manager vs. Runfile Installation: Die Installation über den Package Manager ist bequemer und hat bessere Systemintegration.
- Local Repo Installation vs. Network Repo Installation: Solange die Maschine Internetzugang hat, ist die Network-Repo-Option besser. Damit erhalten wir per apt upgrade die aktuellen Updates von NVIDIA.
- Wir wählen die proprietären Pakete und nicht die Open-Source-Pakete, da die Open-Source-Implementation in vielen Punkten noch deutlich zurücksteht.
Im ersten Schritt sollte geprüft werden, ob bereits Pakete installiert sind, die zu Konflikten führen könnten:
$ dpkg -l | grep nvidia
$ dpkg -l | grep cuda
Diese Ausgabe sollte leer sein. Falls nicht, können bestehende Pakte deinstalliert werden.
Entsprechend dem Abschnitt 3.8.3 aus dem Installationsguide lässt sich der GPG Key und das Repository durch die Installation eines deb-Packages einrichten. (Für $UBUNTU_VERSION wird die jeweilige Version nach dem Muster „ubuntu2404“ eingesetzt.)
$ wget https://developer.download.nvidia.com/compute/cuda/repos/$UBUNTU_VERSION/x86_64/cuda-keyring_1.1-1_all.deb
# dpkg -i cuda-keyring_1.1-1_all.deb
Das Repository wird damit automatisch unter /etc/apt/sources.list.d/cuda-ubuntu2404-x86_64.list angelegt.
Nach einem apt update muss für die Installation des CUDA-Toolkits nur noch ein Meta-Package installiert werden:
# apt install cuda-toolkit
Der zweite Schritt ist die Installation der Kernel-Module. Dafür stellt NVIDIA eine weitere Anleitung bereit. Das Repository ist schon eingerichtet, es kann direkt das Meta-Package installiert werden:
# apt install cuda-drivers
Dies installiert auch eine ganze Reihe an Paketen, die eigentlich nur für Desktops mit Display benötigt werden. Eine compute-only-Variante wird für Fedora, Suse und Debian angeboten, aber zum aktuellen Zeitpunkt nicht für Ubuntu.
Das war’s auch schon. Nach einem Reboot sollten alle Treiber eingerichtet sein.
Die CUDA Binaries befinden sich in /usr/local/cuda-12.8/bin und sollten wie im Abschnitt 10.1.1. Environment Setup beschrieben in den PATH aufgenommen werden.
Eine Erweiterung von LD_LIBRARY_PATH sollte nicht nötig sein, da die Konfiguration durch das entsprechende Ubuntu-Package schon erfolgt ist (/etc/ld.so.conf.d/988_cuda-12.conf).
Verifikation
Um die Installation zu verifizieren, führen wir hier ein paar nützliche Befehle auf.
Prüfen, ob die gewünschte Treiberversion geladen wurde:
$ cat /proc/driver/nvidia/version
NVRM version: NVIDIA UNIX x86_64 Kernel Module 570.133.20 Sun Apr 13 04:50:56 UTC 2025
GCC version: gcc version 13.3.0 (Ubuntu 13.3.0-6ubuntu2~24.04)
Die Installation des CUDA-Compilers NVCC verifizieren:
$ nvcc –version
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Fri_Feb_21_20:23:50_PST_2025 Cuda compilation tools, release 12.8, V12.8.93 Build cuda_12.8.r12.8/compiler.35583870_0
Das NVIDIA System Management Interface (SMI) aufrufen:
$ nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.124.06 Driver Version: 570.124.06 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P40 Off | 00000000:04:00.0 Off | Off |
| N/A 23C P8 9W / 250W | 5MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Tesla P40 Off | 00000000:05:00.0 Off | Off |
| N/A 24C P8 9W / 250W | 5MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
Erste Schritte
Für einen Belastungstest der Grafikkarten nehmen wir gpu-burn. Wie der Name bereits vermuten lässt, treibt dies den Stromverbrauch der GPUs fast ans Limit von 250 Watt pro Einheit.
Im iDRAC sieht man sehr eindrücklich, welche thermischen Auswirkungen das hat: Die Temperatur im Chassis (Volumen ca. 16 Liter) steigt in kürzester Zeit auf 60 °C. Um dies zu bemerken, braucht man allerdings keine Wartungssoftware: Die Lüfter werden markant lauter und schriller und es riecht leicht brenzlig.
Inferenz mit llama.cpp
Um aktuelle Open-Source-Sprachmodelle auszuführen, gibt es eine Reihe populärer Software wie KoboldCpp und ollama, die eins gemeinsam haben: Sie setzen auf die Bibliothek llama.cpp, die im Hintergrund die eigentliche „harte Arbeit“ übernimmt. Für erste Tests bietet es sich an, direkt mit llama.cpp zu arbeiten – und das aus mehreren Gründen:
- maximale Kontrolle bei der Konfiguration und Optimierung
- detaillierte Ausgabe von Parametern und Hardwareeigenschaften
- neue Modelle erfordern oft aktuelle Features – und die landen meist zuerst in llama.cpp
Es empfiehlt sich, llama.cpp direkt aus den Quellen zu kompilieren:
$ cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/opt/llama-cpp -DLLAMA_BUILD_EXAMPLES=ON -DLLAMA_BUILD_SERVER=ON
$ cmake --build build --config Release -j 16
Optional, Installation der Binaries nach /opt/llama-cpp:
$ sudo cmake --install build
Kompilieren aus Quellen
Beim Kompilieren aus den Quellen wird man nicht selten erstmal mit kryptischen Fehlern konfrontiert. Davon sollte man sich jedoch nicht verunsichern lassen.
- Grundvoraussetzung sind Entwicklungswerkzeuge wie
cmakeundg++, die auf dem System installiert sein müssen. Empfehlenswert ist das Meta-Paketbuild-essential, das die wichtigsten Tools bündelt.- In der Regel fehlen zusätzlich sogenannte Dev-Pakete für benötigte Bibliotheken. Leider wird dabei oft nicht direkt angegeben, welches Paket konkret installiert werden muss – diese Information muss man aus der Fehlermeldung ableiten. So erwartet beispielsweise
llama.cppdie Entwicklungsdateien fürcurl, die im Paketlibcurl4-openssl-deventhalten sind.
Download der Modelle
Sprachmodelle findet man auf https://huggingface.co/. Um ein Model in llama.cpp zu nutzen, muss es im gguf-Format vorliegen.
Die Konvertierung kann man problemlos selbst durchführen. Dazu liefert llama.cpp die Tools convert_hf_to_gguf.py und llama-quantize mit. Für populäre Modelle findet man aber oft schon vorkonvertierte Modelle im gguf-Format auf Huggingface.
Jetzt gilt es noch, sich für eine Quantisierung zu entscheiden. Mit kleinerer Quantisierung verbraucht das Modell weniger vRAM, die Ausführung wird schneller, aber die Leistungsfähigkeit ist vermindert. Starten kann man mit der größten Ausführung, die noch in den vRAM passt und dann verringern, falls die Geschwindigkeit nicht ausreichend ist. Eine 4-Bit-Quantisierung ist in der Regel ein guter Kompromiss: Der vRAM wird effizient genutzt, während die Leistungseinbußen gering bleiben.
Fertige gguf-Files können wir mit dem Hugging Face CLI-Tool laden, das sich mit folgendem Befehl installieren lässt:
$ pip install -U "huggingface_hub"
Alternativ kann die aktuelle Version des Tools auch ohne Installation mit uvx direkt ausgeführt werden. Ein entsprechender Alias könnte so aussehen:
$ alias hf="uvx --from huggingface_hub hf"
Der eigentliche Download in das aktuelle Verzeichnis sieht dann zum Beispiel so aus:
$ hf download bartowski/Qwen_Qwen3-30B-A3B-GGUF --include "Qwen_Qwen3-30B-A3B-Q4_K_M.gguf" --local-dir .
Chat in der Commandozeile
llama.cpp stellt eine Reihe von Kommandozeilen-Tools zur Verfügung. Mit llama-cli lässt sich direkt ein Chat starten:
$ llama-cli -m ~/models/bartowski/Qwen_Qwen3-30B-A3B-GGUF/Qwen_Qwen3-30B-A3B-Q4_K_M.gguf -co -cnv -fa -ngl 99
Die Bedeutung der Commandozeilenparameter:
- -m: Pfad zur GGUF-Modell-Datei.
- -co: Farbige Ausgabe zur besseren Unterscheidung von Eingaben und Antworten.
- -cnv: Aktiviert den Gesprächsmodus (Conversation Mode).
- -fa: Schaltet Flash Attention ein (wenn vom Modell unterstützt).
- -ngl 99: Lässt bis zu 99 Modell-Layer auf der GPU berechnen.
Der Parameter -ngl 99 weist llama.cpp an, bis zu 99 Modell-Layer auf der GPU zu verarbeiten. In der Praxis bedeutet es, dass sämtliche Layer ausgelagert werden – wie auch die Ausgabe bestätigt:
offloaded 49/49 layers to GPU
Falls nicht alle Layer auf die GPU passen, werden die verbleibenden auf der CPU verarbeitet – was erwartungsgemäß zu deutlichen Performanceeinbußen führt.
Benchmarks
Ein Hauptziel dieses Setups ist es, eine ausreichende Menge vRAM zu einem angemessenen Preis zu bekommen. Aber am Ende des Tages möchten wir nicht nur riesige Modelle laden, sondern diese auch zügig ausführen. Das Rack sollte sich an dem messen lassen, was sich Freunde und Kollegen an Consumer-Hardware so auf den Schreibtisch stellen. Ein Spitzenreiter ist dabei die Apple-Silicon-M-Serie, mit ihrer Unified Memory Architecture.
Als Referenz nutzen wir ein ausführliches Community-Benchmark der verschiedenen Apple-Produkte. Hier wird ein kleineres Modell (Llama 7B v2) getestet. Es lässt sich auf unserem Setup vielfach parallel ausführen, aber dennoch ist auch die maximale Geschwindigkeit entscheidend.
Mit dem Tool llama-bench ermitteln wir zwei Geschwindigkeiten
- pp (prompt parsing): Lesen der Frage/des Prompts, was ja auch mal länger sein kann
- tg (text generation): Erzeugen der Antwort
$ llama-bench -m llama-2-7b.Q8_0.gguf -m llama-2-7b.Q4_0.gguf -p 512 -n 128 -ngl 99 -fa 1
| model | size | params | backend | ngl | fa | test | t/s |
|---|---|---|---|---|---|---|---|
| llama 7B Q8_0 | 6.67 GiB | 6.74 B | CUDA | 99 | 1 | pp512 | 1024.05 ± 0.74 |
| llama 7B Q8_0 | 6.67 GiB | 6.74 B | CUDA | 99 | 1 | tg128 | 36.18 ± 0.01 |
| llama 7B Q4_0 | 3.56 GiB | 6.74 B | CUDA | 99 | 1 | pp512 | 1073.58 ± 0.35 |
| llama 7B Q4_0 | 3.56 GiB | 6.74 B | CUDA | 99 | 1 | tg128 | 55.80 ± 0.83 |
build: 578754b3 (5117)
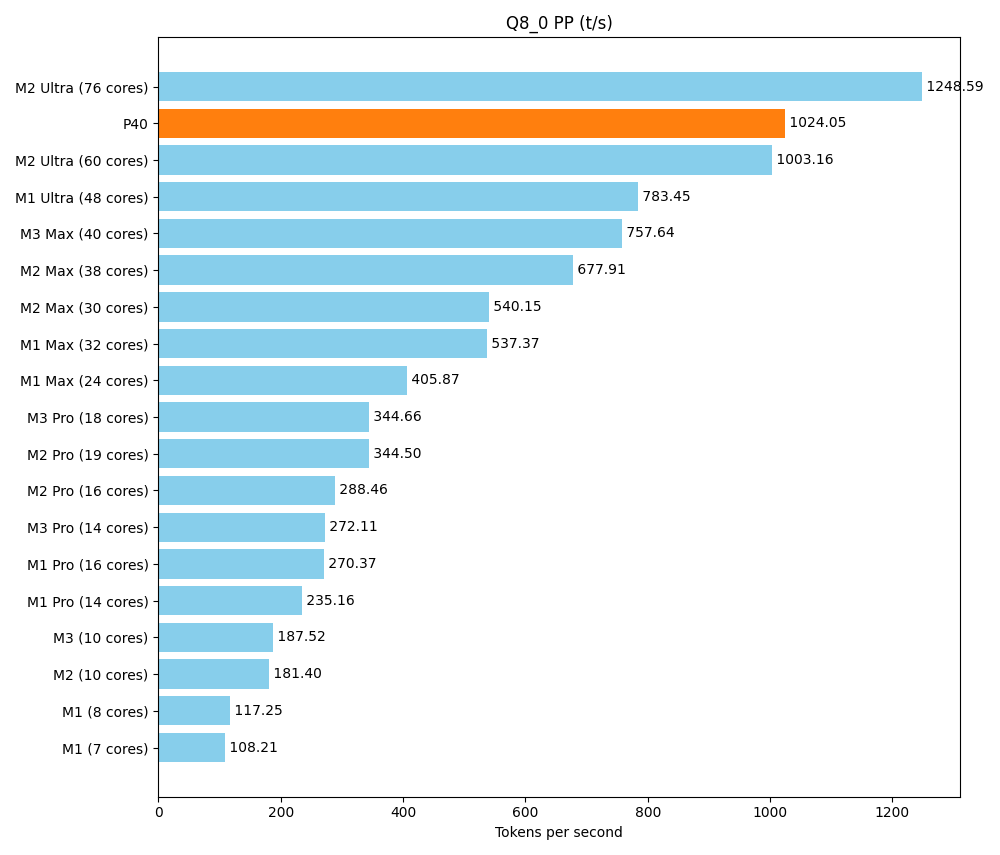
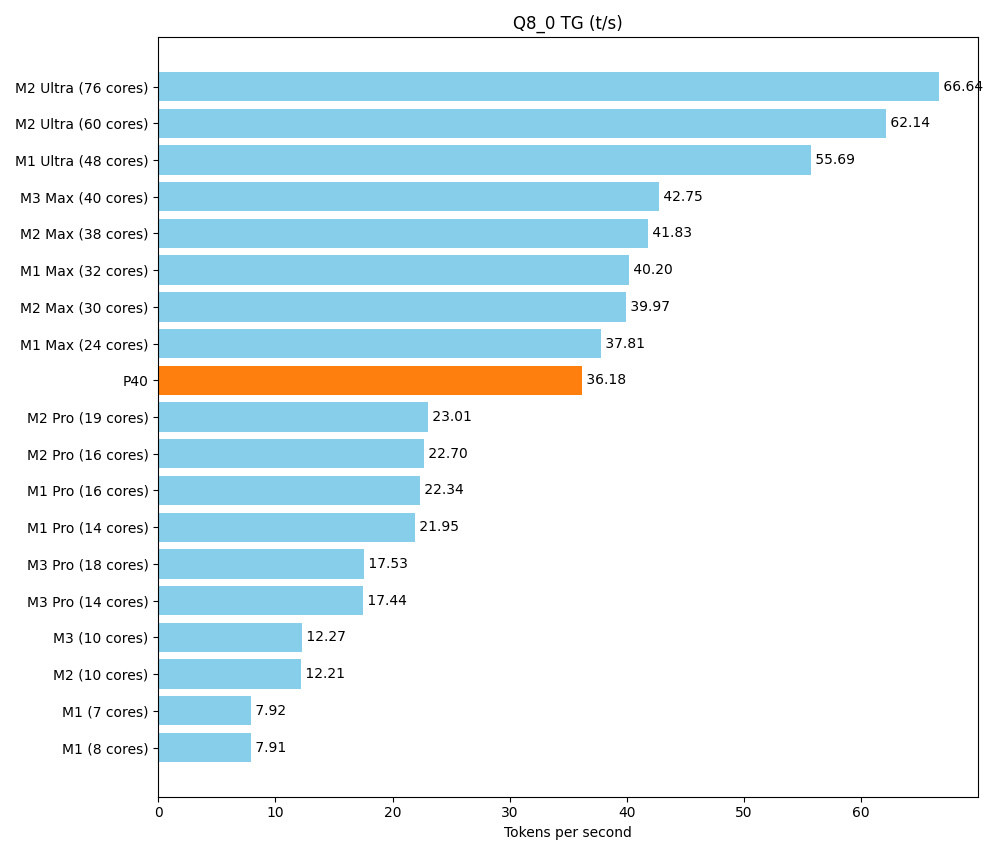
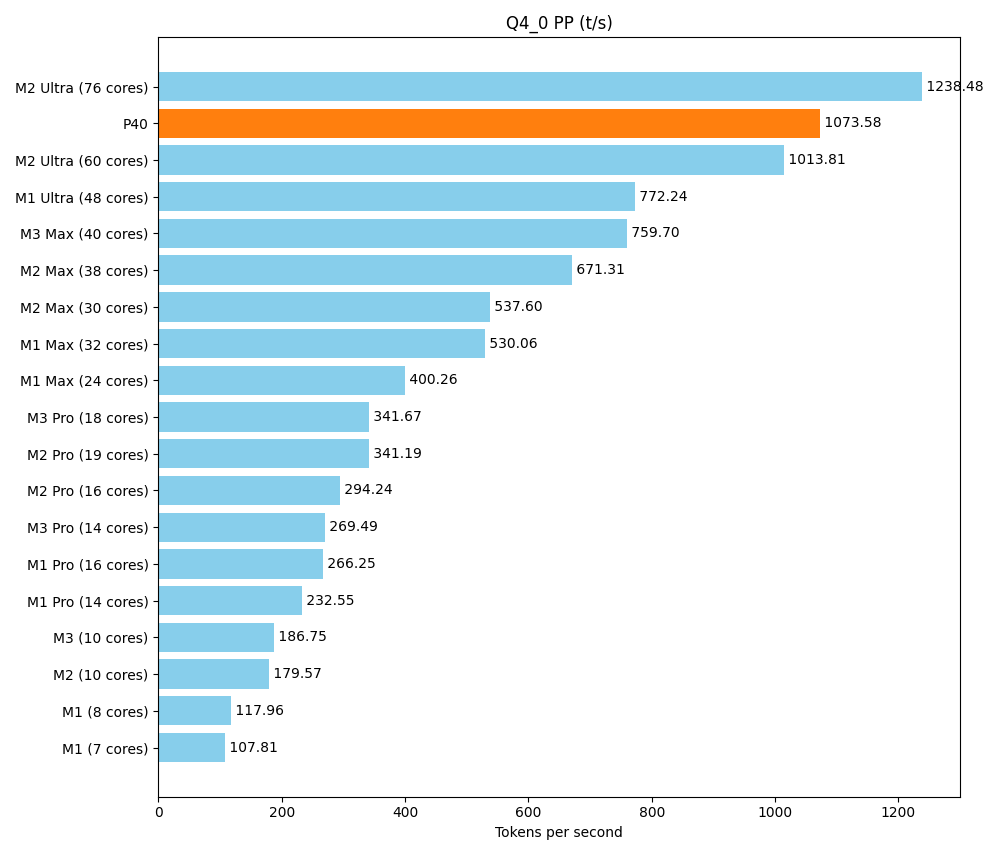
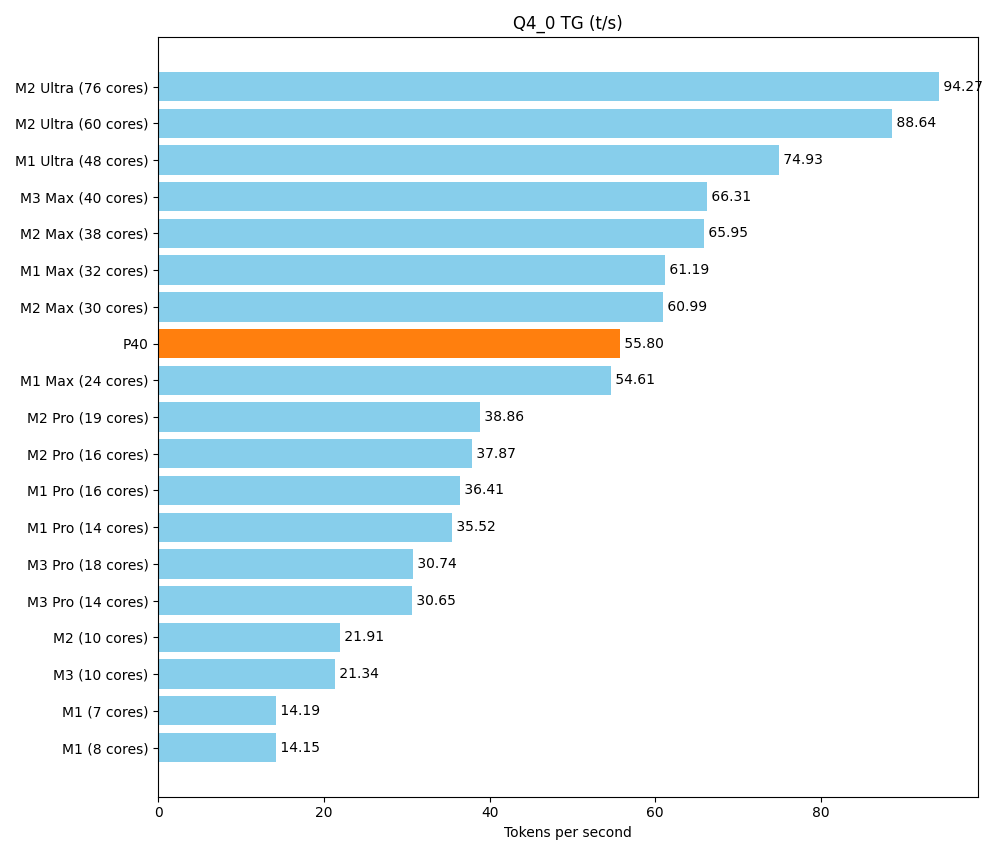
Im Bereich Prompt-Parsing schlägt sich der P40 hervorragend. Bei der Textproduktion liegt er oberhalb der Pro-Reihe und im unteren Bereich der Max-Reihe.
Fazit
Mit einem überschaubaren Budget haben wir einen leistungsfähigen HPC-Server mit insgesamt 96 GB vRAM aufgebaut und damit eine solide Basis für anspruchsvolle KI- und Datenverarbeitungsprojekte geschaffen.
Mietserveralternativen
Der Einsatz gemieteter KI-GPU-Server kann je nach Szenario eine sinnvolle Option sein. Wer lediglich punktuell Trainingsphasen benötigt oder kurzfristig Prototypen testen möchte, profitiert von stundenbasierten Mietangeboten. Bei langfristigem, kontinuierlichem Einsatz, insbesondere bei dedizierten Ressourcen mit vollem Zugriff, summieren sich die Kosten jedoch schnell. Im Bereich von 1.000 EUR pro Monat sind solche Setups keine Seltenheit, was den eigenen Betrieb auf Dauer wirtschaftlich attraktiver macht.
Praktische Rahmenbedingungen
Der Betrieb eines leistungsstarken Servers bringt jedoch nicht nur Vorteile, sondern auch infrastrukturelle Anforderungen mit sich:
- Platz & Lautstärke: Unter Volllast ist ein geeigneter Serverraum mit ausreichender Belüftung notwendig.
- Energiebedarf: Dauerhafte Auslastung kann Stromkosten im Bereich von 100 EUR pro Monat oder mehr verursachen.
- Wartung & Updates: Treiber- und Softwareupdates, Reparatur und Erneuerung defekter Hardware liegen in der eigenen Verantwortung.
- Begrenzte Treiber-/Softwarekompatibilität gebrauchter Hardware: In unserem Fall wurde die GPU-Architektur „Pascal“ des P40 noch gut unterstützt und wir können aktuelle Modelle betreiben. Wir sind hier aber gerade an der Grenze und an einigen Stellen gibt es schon Deprecation-Warnungen. Vor der Anschaffung sollte der aktuelle Support für Treiber (CUDA) und den wichtigen Bibliotheken und Frameworks (insbesondere PyTorch) recherchiert werden.
Mehrwert für das Team
Für unser Team ist der aktuelle Aufbau ein echter Gewinn:
- Freies Experimentieren: Keine Genehmigungsprozesse oder Zeitdruck durch teure Mietstunden.
- Datensouveränität: Lokale LLMs und KI-Modelle ermöglichen es, auch vertrauliche Daten sicher zu verarbeiten.
- Volle Kontrolle: Wir bestimmen über Hardware, Software und Zugriffsrechte. Alles kann ausprobiert werden, egal wie obskur.
