
Yolo?
Nein, mit YOLO ist diesmal nicht das Jugendwort oder die typische Abkürzung gemeint, sondern YOLO, das neuronale Netz für Objekterkennung. Was Objekterkennung überhaupt ist, wie neuronale Netze für Objekterkennung funktionieren und wie man YOLO beibringt Spieler aus dem Computerspiel VALORANT zu erkennen, zeigen wir in diesem Blog-Artikel.
Maschinelles Sehen
Maschinelles Sehen ist, wie der Name schon sagt, die Fähigkeit von Computern sehen zu können. Sie können Bilder auswerten und Informationen in digitaler Form daraus extrahieren, zum Beispiel können sie Objekte in einem Bild erkennen, identifizieren und umranden. Bei der Erkennung von komplexeren Objekten, wie zum Beispiel dem Spieler in Valorant, kommt oft künstliche Intelligenz zum Einsatz, genauer gesagt neuronale Netze.

dog.jpg: Predicted in 23.210000 milli-seconds.
bicycle: 91% (left_x: 114 top_y: 127 width: 458 height: 299)
dog: 98% (left_x: 129 top_y: 225 width: 184 height: 316)
truck: 92% (left_x: 464 top_y: 76 width: 221 height: 94)(Quelle: darknet repository)
YOLO!
Ein solches neuronales Netz ist YOLO: Man gibt dem neuronalen Netz ein Bild als Eingabe und bekommt eine Liste von erkannten Objekten zurück, die den Namen (Class) des Objektes, die Position (Bounding-Box) und die Wahrscheinlichkeit, dass es sich wirklich um dieses Objekt handelt. Ein Beispiel für so eine Liste seht ihr in der Abbildung oben. Die Besonderheit von YOLO ist die kurze Zeit, die das Netz für die Erkennung braucht (Inference-Time), was schon der Name der Software ausdrückt: “You only look once”. Andere Erkennungssysteme wie zum Beispiel R-CNN wenden das Netz auf viele verschieden große Ausschnitte des Bildes an und nehmen dann die höchst gepunkteten Ausschnitte als Bounding-Boxes. Da dies allerdings ungefähr immer 2000 Ausschnitte pro Bild sind, braucht die Erkennung dementsprechend lange. YOLO hingegen “schaut” sich das Bild nur einmal an und entscheidet dann, wo welche Objekte zu erkennen sind. Um diese Entscheidung zu treffen, teilt YOLO sich das Bild in ein Gitter mit vielen Teilabschnitten ein. Für jede Box wird dann die Klasse des sich darinbefindenden Objekts bestimmt, sowie die Zuversicht des Netzes, das dies richtig ist. Wenn man jetzt die Zuversicht auf 30 % oder darüber begrenzt, erhält man auch vernünftige Ergebnisse.

(Quelle: YOLO site)
Diese Methodik hat abgesehen von der niedrigen Inference-Time auch den Vorteil, dass das Netz für die Vorhersagen Informationen aus dem Kontext des kompletten Bildes entnehmen kann und nicht nur aus dem Ausschnitt, den es sich gerade anguckt. Dadurch, dass sich das Netz das Bild lediglich einmal anschaut, ist die Genauigkeit der Vorhersagen aber auch schlechter als zum Beispiel bei R-CNNs. Dazu kommt ein Problem, das die Gitter-Aufteilung mit sich bringt: Weil YOLO nur eine Vorhersage pro Kachel macht, tut es sich sehr schwer damit kleine Objekte korrekt zu erkennen. Wenn man also zum Beispiel eine Anwendung entwickeln möchte, die in der Lage ist, die Vögel in einem Vogelschwarm zu zählen, sollte man dementsprechend nicht YOLO wählen. Im Fall der Gegner-Erkennung in Valorant bietet sich YOLO allerdings an, da A) wir eine möglichst schnelle Erkennung wollen und B) die Spieler meistens groß genug auf dem Bildschirm zu sehen sind.

Quelle: Bild aus dem Spiel Valorant
Wie man YOLO beibringt VALORANT-Gegner zu erkennen
Wie wir gerade eben festgestellt haben, eignet sich YOLO gut für unseren Anwendungsfall (Use-Case). Jetzt müssen wir es
allerdings noch schaffen, dass YOLO lernt die Gegner zu erkennen. Um ein neuronales Netz zu trainieren braucht man
primär drei Dinge: viele Trainingsdaten, viel Rechenleistung und viel Zeit. Die Trainingsdaten bestehen hierbei aus
vielen Trainingspaaren, die immer aus einem Bild und einer zugehörigen Textdatei mit den Objekten, die das Netz erkennen
soll, und deren Position. Die Textdatei besteht immer aus einem zu erkennendem Objekt pro Zeile:
<object-class_id> <x_center> <y_center> <width> <height> mit:
<object_class_id>: die Klassennummer des Objekts (z.B. player = 0 und head_player = 1)<x_center> <y_center>: die Mitte der Bounding-Box relativ zu der Breite und Höhe des Bildes (also Werte von 0.0 bis 1.0)<width> <height>: die Breite und Höhe der Bounding-Box relativ zu der Breite und Höhe des Bildes

Quelle: Bild aus dem Spiel Valorant
0 0.365966 0.477610 0.059402 0.296767
1 0.374505 0.355427 0.015204 0.052402
Beim Trainingsprozess schaut sich YOLO die Trainingspaare stapelweise an, trifft eine Vorhersage und korrigiert daraufhin die sogenannten Gewichte (das sind die inneren Einstellungen des Netzes, die das Verhalten des Netzes bestimmen) so, dass die nächste Vorhersage näher an der gewünschten Vorhersage für dieses Trainingsbild liegt. Während des Trainings wird diese Prozedur einfach X mal wiederholt (X Iterationen). Mit jeder Iteration sinkt die Abweichung zwischen gewünschter Vorhersage und aktueller Vorhersage, auch Loss genannt. Je kleiner der Loss wird, desto “ festgefahrener” (und unflexibler) wird das Netz allerdings auch. Ein extrem geringer Loss bedeutet, dass das Netz die Objekte auf den Trainingsbildern zwar sehr gut erkennt, allerdings Objekte auf anderen (unbekannten) Bildern sehr schlecht bis gar nicht erkennt. Das Gegenstück zu dem oben genannten Festfahren (Overfitting) nennt sich Underfitting. Underfitting hat zur Folge, dass das Netz sich einerseits bei der Erkennung sehr unsicher ist und andererseits auch viele Objekte nicht oder sogar fälschlich erkennt, sogenannte False-Positives. Die Fähigkeit des Netzes, neben den Objekten auf Trainingsbildern auch die gleichen Objekte auf neuen Bildern zu erkennen, nennt man generalisieren. Im optimalen Stadium sollte das Netz eine gesunde Mischung zwischen Präzision bei der Erkennung und Generalisierung haben. Um ungefähr zu wissen, wann man dieses optimale Stadium erreicht hat und das Training abbrechen kann/sollte, hilft eine Daumenregel: circa 2000 Iterationen pro Klasse, mindestens aber 6000 Iterationen. Wenn man genauer wissen möchte, wann man am besten mit dem Training aufhören sollte, braucht man neben den Trainingsdaten auch sogenannte Validierungsdaten. Diese sind genauso aufgebaut wie die Trainingsdaten, bestehen also auch aus vielen Bild-Text-Paaren. Einziger Unterschied ist, dass das neuronale Netz die Validierungsdaten nicht zum Trainieren, sondern lediglich zum Überprüfen benutzt. Alle 100 Iterationen trifft das Netz seine Vorhersagen für die Validierungsbilder und überprüft deren Genauigkeit gemessen in z.B. mAP, der Mean-Average-Precision. Um den richtigen Zeitpunkt für das Trainingsende zu finden, hilft das folgende Diagramm eines typischen Trainingsvorgangs.
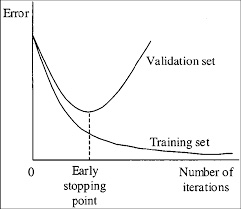
(Quelle: darknet repository)
Man sieht, wie der Loss/Error für die Trainingsdaten im Laufe des Trainingsverlaufs kontinuierlich abnimmt (das Netz erkennt jedes der Trainingsbilder immer besser). Der Fehler des Netzes bei den Vorhersagen für das Validierungsset (eine Sammlung aus dem Netz unbekannter Bilder) hingegen sinkt nur bis zum Early-Stopping-Point. Danach ist das Netz immer weniger in der Lage zu generalisieren und erkennt im Extremfall (sehr viele Iterationen) nur noch die Bilder aus dem Trainingsdatenset. Das Training sollte gestoppt werden, wenn dieser Early-Stopping-Point” erreicht ist.
Ich habe bei der VALORANT-Spieler-Erkennung bereits nach 3000 Iterationen das Training abgebrochen, nicht weil der Early-Stopping-Point erreicht war, sondern weil ich einfach zu ungeduldig war :). Denn das Training braucht Zeit, viel Zeit: Für die 3000 Iterationen hat mein Computer ca. 12 Stunden durchgehend gerechnet - und mein Netz soll nur 2 Klassen (Spieler und deren Köpfe) erkennen. Wenn man ein Netz trainieren möchte, das 80 verschiedene Objekte erkennen soll wie für das Referenztrainingsset COCO, dann braucht das Training auch gerne mal mehrere Tage. Aber wie für jedes Problem gibt es auch hierfür eine Lösung: Je größer der Grafikspeicher der Grafikkarte ist, desto mehr Bilder kann sich YOLO beim Training auf einmal anschauen, desto schneller ist es dementsprechend auch. Also: Zeit sich eine neue Grafikkarte zuzulegen! Nach dem Training ist es dann an der Zeit sich die Ergebnisse des Trainings anzuschauen. Wie man sieht, sind die Ergebnisse trotz zu kurzem Trainings gut geworden, allerdings kann man das Underfitting anhand von einem anderen Aspekt erkennen: Wenn man dem neuronalen Netz Bilder von einem anderen Spiel gibt, in unserem Fall CS:GO, erkennt es trotzdem - obwohl die Spieler ganz anders aussehen - weiterhin die Gegner. Aber besonders im zweiten Bild ist gut zu sehen, dass zwar der Spieler auf der rechten Seite richtig erkannt worden ist, allerdings die Waffe links auch als Spieler eingestuft worden sind.

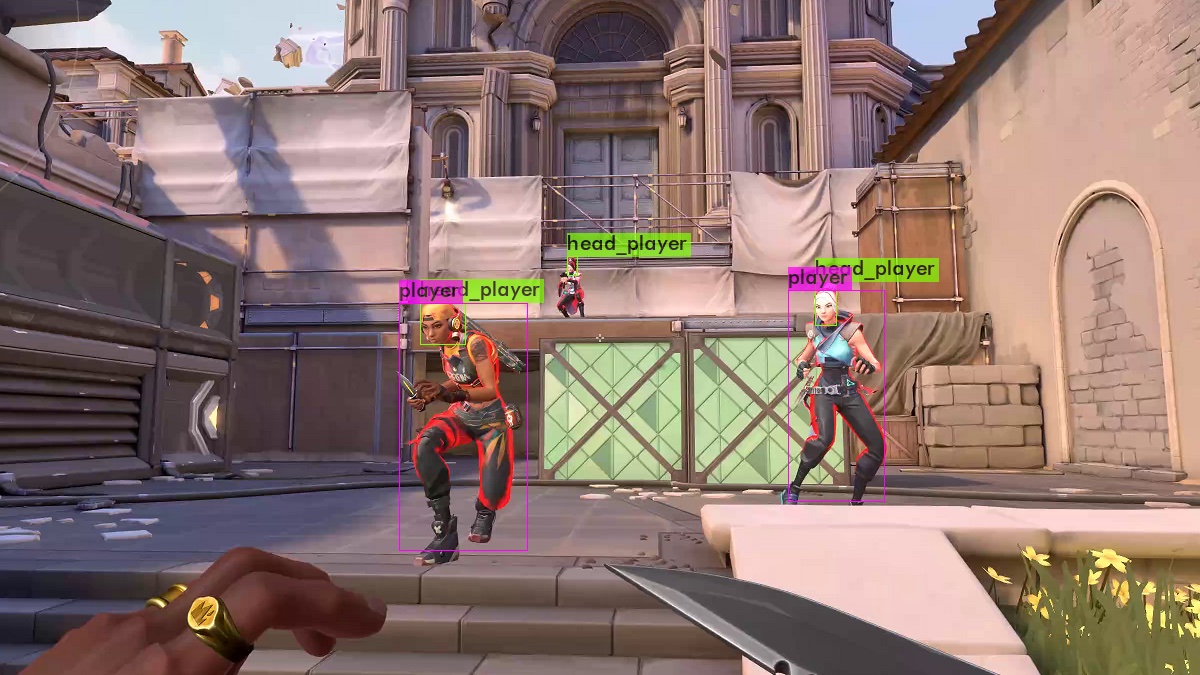
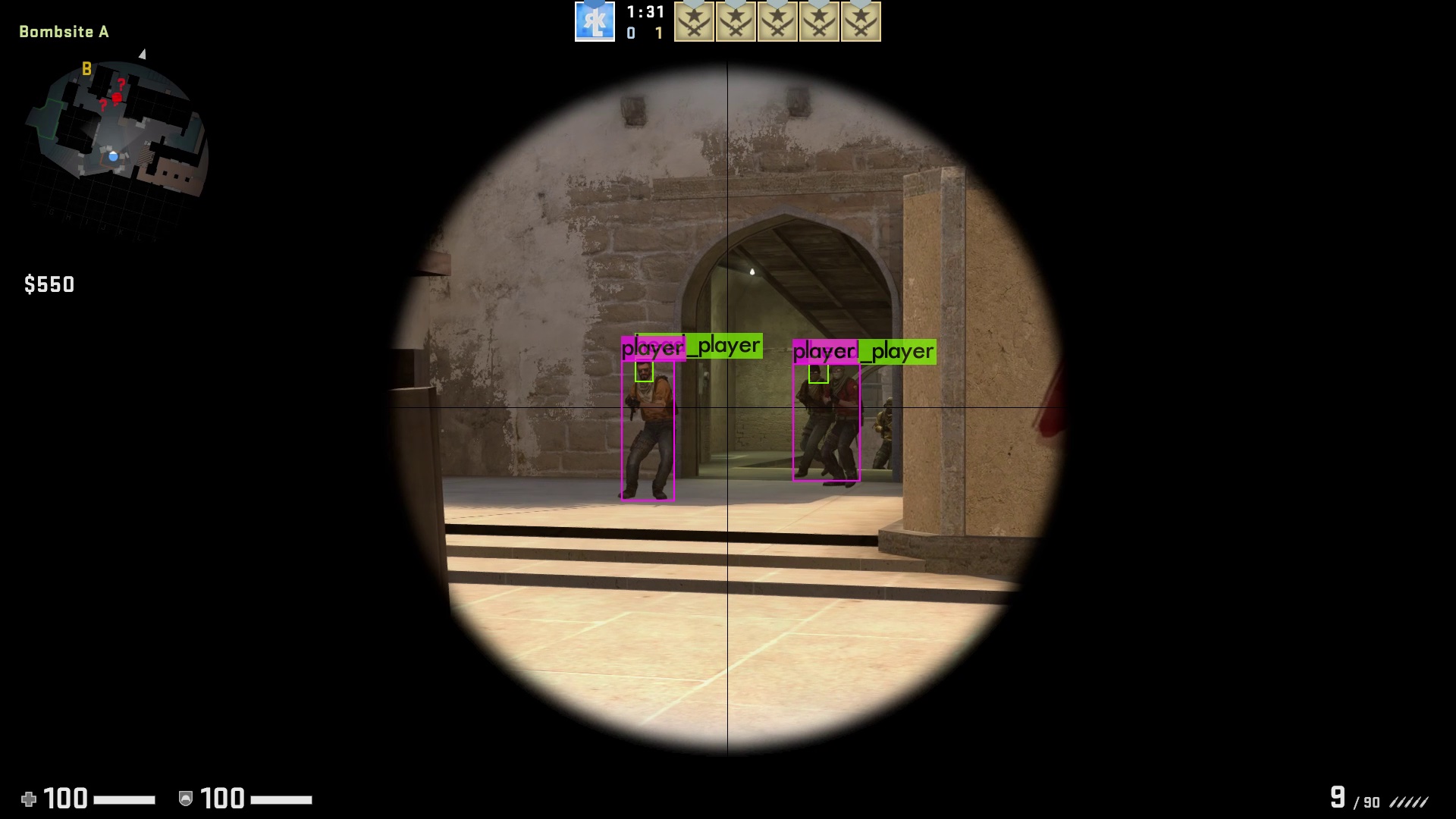
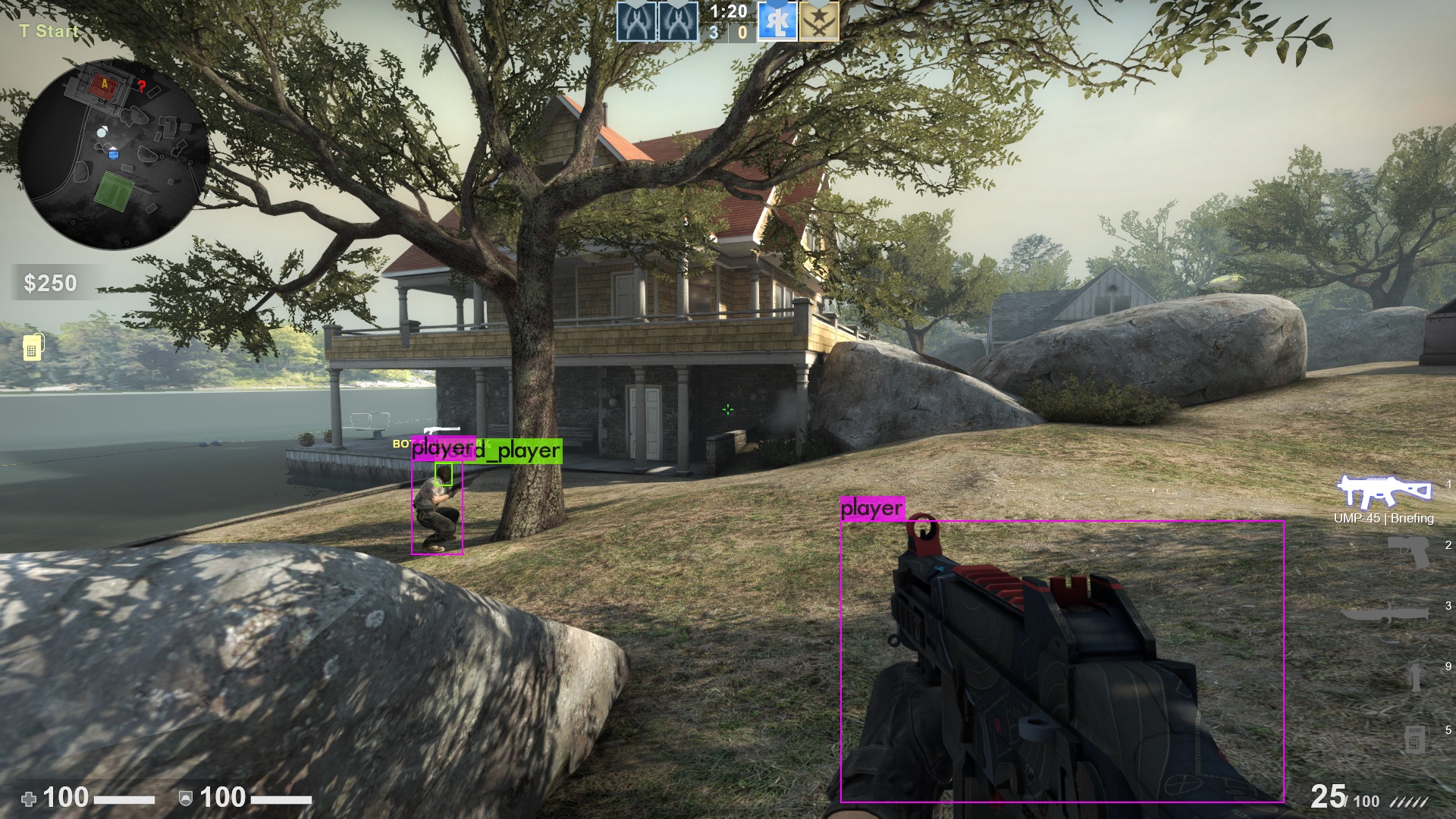
Die Gegner-Erkennung in ein Beispielprogramm einbinden
Damit wir unser neuronales Netz noch besser testen können, werden wir im letzten Schritt eine kleine C#-Anwendung schreiben, die live einen Bereich unseres Bildschirm kopiert, unser Netz auf diesen Bereich anwendet und die Ergebnisse in einem Fenster anzeigt. Bevor wir starten können, müsst ihr sicherstellen, dass ihr alle Anforderungen erfüllt (die Liste der Anforderungen findet ihr hier). Als Einstieg müssen wir unser neuronales Netz natürlich erst laden. Zum Laden und für die Erkennung später benutzen wir den Alturos.Yolo-Wrapper:
Console.WriteLine("Starting YOLO object detection ...");
var gpuConfig = new GpuConfig();
var yoloConfig = new YoloConfiguration("yolov4-valorant.cfg", "yolov4-valorant_last.weights", "valorant.names");
using (var yoloWrapper = new YoloWrapper(yoloConfig, gpuConfig))
{
Außerdem brauchen wir einen Main-Loop, in dem
- Immer wieder das Bild ausgeschnitten wird
Rectangle capRegion = new Rectangle(1920 / 2 - 1200 / 2, 1080 / 2 - 675 / 2, 1200, 675); Bitmap bmp = cap.CaptureRegion(capRegion); - Unser neuronales Netz Vorhersagen für das ausgeschnittene Bild (im passenden Format) trifft
byte[] jpgBytes = (byte[]) new ImageConverter().ConvertTo(bmp, typeof(byte[])); var items = yoloWrapper.Detect(jpgBytes); - Und wir die Vorhersagen auf das Bild zeichnen und dann anzeigen
using (Graphics g = Graphics.FromImage(bmp)) { if (items.GetEnumerator().MoveNext()) { foreach (var item in items) { Color color = Color.Black; switch (item.Type) { case "player": color = Color.LawnGreen; break; case "head_player": color = Color.Red; break; } g.DrawRectangle(new Pen(color), item.X, item.Y, item.Width, item.Height); g.DrawString(item.Type + "(" + Math.Round(item.Confidence * 100) + "%)", new Font(FontFamily.GenericMonospace, 15), new SolidBrush(color), item.X, item.Y); } } } form.pictureBox1.Image = bmp;
Wenn man möchte, kann man noch einen FPS-(Frames-Per-Second)-Counter hinzufügen, um die Performance messen zu können. Dabei muss man allerdings im Hinterkopf behalten, dass diese Beispiel-Anwendung nicht performance-optimiert ist (weder die Objekterkennung noch die Bildschirmaufnahme). Implementieren kann man den Counter ganz einfach über eine Stoppuhr, die am Anfang jeder Iteration zurücksetzt und am Ende die Zeit wieder gestoppt und angezeigt wird.
Stopwatch watch = new Stopwatch();
watch.Restart();
watch.Stop();
g.DrawString((1000 / watch.ElapsedMilliseconds) + "FPS (" + watch.ElapsedMilliseconds + "ms)",
new Font(FontFamily.GenericMonospace, 15), new SolidBrush(Color.LimeGreen), 10, 10);
Jetzt fehlt nur noch ein kleiner Teil, bevor der Code funktioniert. Euch ist bestimmt nicht entgangen, dass wir
bei cap.CaptureRegion(capRegion) die Variable cap benutzen, die gar nicht existiert. Diese Variable wird vor dem
Loop deklariert:
cap = new ScreenCapture();
und ist ein Objekt unserer selbstgeschriebenen Klasse ScreenCapture. Ich werde hier nicht im Detail auf diese Klasse
eingehen, weil sie so ziemlich das macht, was sie sagt: den Bildschirm aufnehmen. Wenn jemand mehr darüber erfahren
möchte, ist hier der Link zu dem Artikel,
den ich zum Erstellen der Klasse benutzt habe.
Ihr habt es geschafft! Die Anwendung sollte jetzt voll funktionstüchtig sein und die Gegner auf eurem Bildschirm erkennen. Mehr Informationen über die Anforderungen und den vollständigen Source-Code findet ihr hier auf GitHub. Wer keine Lust oder keine Zeit hat das Projekt selber zu bauen und auszuprobieren, kann sich das Demo-Video der Anwendung hier anschauen.
