
Hüter der Datenhistorie
Audit-Verfahren sind im Bereich des Datenmanagements unverzichtbar. Sie fungieren als Hüter der Datenhistorie und gewährleisten, dass jede Änderung an Daten nicht nur nachverfolgt, sondern auch detailliert festgehalten wird. Audit-Methoden ermöglichen uns eine Art Zeitreise durch die Datenhistorie, um zu verstehen, wer, wann und welche Änderungen vorgenommen hat.
Für Entwickler ist es daher wichtig, effektive Audit-Techniken für spezifischen Anwendungen und Anforderungen zu kennen. In diesem Artikel stelle ich die Unterschiede zwischen den Java-basierten Tools Hibernate Envers, JPA Data und dem Einsatz von Datenbank-Triggern für das Auditing vor. Anhand einer Beispielanwendung mit Spring Boot, Spring Security, JPA Data und Hibernate ORM untersuchen wir, welcher Ansatz für verschiedene Szenarien am besten geeignet ist.
Ein Blick auf die Grundlagen: Change Data Capture
Change Data Capture (CDC) ist ein Verfahren, das Datenänderungen in einer Datenbank in Echtzeit an ein nachgelagertes System übermittelt. Diese Technik ist das Fundament jedes Audit-Systems, denn jeder Audit-Prozess muss über Änderungen an den überwachten Daten informiert werden. Solche Änderungen können Einfüge-, Update- oder Löschoperationen in der Datenbank sein. Das Erkennen dieser Änderungen erfolgt entweder durch Aufzeichnung oder durch Auslösen eines Trigger-Ereignisses.
In der Java-Welt: Hibernate Envers
Hibernate Envers bietet eine CDC-Lösung speziell für Java-Anwendungen, die das Auditing vereinfacht. Die nahtlose Integration mit Hibernate ORM ermöglicht es, innerhalb des Java-Ökosystems zu bleiben. Das System nutzt eine zentrale REVINFO-Tabelle sowie spezifische Tabellen für jede Entität. Um eine Entität zu auditieren, genügt es, diese mit der Annotation @Audited zu versehen.
Envers setzt auf einen Deny-Listing-Ansatz. Eigenschaften werden also standardmäßig auditiert – es sei denn, sie werden explizit ausgenommen. Das wird besonders dann deutlich, wenn die Datenbank an ihre Grenzen stößt, weil man vergessen hat, große Dateien vom Audit auszunehmen. Betrachten wir dazu ein einfaches Beispiel: Eine Entität namens Dog mit Eigenschaften wie Name und Größe wird für das Auditing annotiert.
@Audited
@Entity
public class Dog {
@Id
private Long id;
private String name;
private Integer height;
//Getters and setters
}
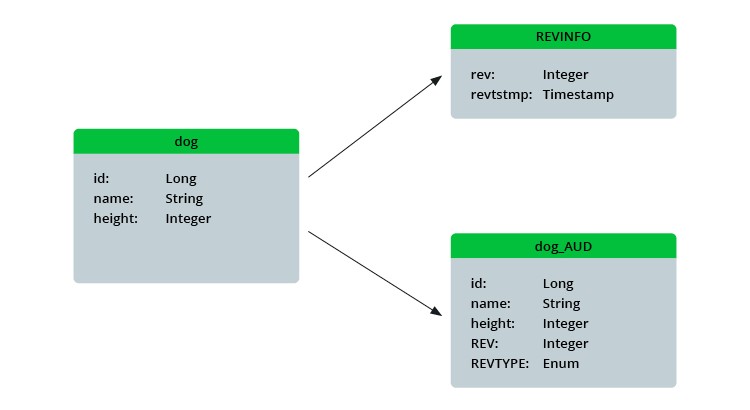
Daraus erzeugt Hibernate drei spezifische Tabellen, wie in der folgenden Abbildung dargestellt.
Zu diesen Tabellen zählen die Übersicht der auditierten Entitäten, die REVINFO-Tabelle und die Tabelle für die Überprüfung der Entitäten selbst. Die REVINFO-Tabelle setzt sich aus der Revisions-ID und einem Zeitstempel zusammen. Diese Revisions-ID korrespondiert mit der in der Tabelle für die Entitätsprüfung, die neben der Revisions-ID und den Entitätseigenschaften auch eine Spalte REVTYPE enthält. Diese Spalte kennzeichnet den Typ der durchgeführten Änderung, was bedeutet, dass die Audittabelle eine vollständige Historie jeder Revision einer Entität bewahrt. Das ist besonders nützlich, wenn man den Zustand einer Entität zu einem bestimmten Zeitpunkt rekonstruieren möchte, etwa um ihn mit dem aktuellen Zustand zu vergleichen.
Envers bietet umfangreiche Konfigurationsmöglichkeiten, um sämtlichen Anforderungen an das Auditing gerecht zu werden. Das reicht vom Ausschluss bestimmter Eigenschaften von der Auditierung bis hin zur individuellen Anpassung der Auditing-Tabellen. Weitere Informationen dazu findet man in der offiziellen Dokumentation.
Um Audit-Daten abzurufen, bietet Envers die AuditReaderFactory an, die es ermöglicht, alle Zustandsschnappschüsse einer Entität zu ermitteln. Für unser Beispiel mit der Entität Dog und der Objektinstanz-ID „1“ würde das folgendermaßen aussehen:
List<Dog> snapshots = AuditReaderFactory.get(entityManager).createQuery()
.forRevisionsOfEntity( Dog.class, true, true)
.add(AuditEntity.id().eq(1L))
.getResultList();
Vorteile:
-
In der Java-Welt: Hibernate Envers ermöglicht einen reibungslosen Übergang zu Auditing-Systemen, alles innerhalb des Java-Ökosystems.
-
Automatische Tabellengenerierung: Envers erleichtert die Einrichtung von Auditing-Tabellen durch automatische Generierung, auch für Datenbanken wie PostgreSQL. Werkzeuge wie LiquiBase können diesen Prozess noch weiter vereinfachen.
-
Datenbank-agnostisch: Ein besonderer Vorteil von Envers ist seine Datenbank-Unabhängigkeit. Dadurch ist man ist nicht auf einen bestimmten Datenbanktyp festgelegt und kann flexibel mit verschiedenen Datenbanksystemen arbeiten, sei es PostgreSQL, MariaDB oder andere.
-
Revision zu einem bestimmten Zeitpunkt: Mit Envers kann man auf Daten zugreifen, wie sie zu einem bestimmten Zeitpunkt vorlagen, und so detaillierte Einblicke in historische Daten oder für Vergleichsanalysen gewinnen.
Nachteile:
-
Performance Overhead: Envers fügt jeder Transaktion zusätzliche SQL-Operationen hinzu, einschließlich Einfügungen, Aktualisierungen und Löschvorgänge. Diese notwendigen Operationen können aufgrund ihrer synchronen Natur die Gesamtperformance beeinträchtigen.
-
Beschränkte Datenquelle: Envers konzentriert sich hauptsächlich auf Änderungen, die innerhalb der Anwendung durchgeführt werden. Änderungen, die über SQL-Konsolen oder durch andere externe Anwendungen erfolgen, könnten daher übersehen werden.
-
Fehlende Unterstützung für Bulkoperationen: Envers bietet keine spezielle Unterstützung für Bulkaktualisierungen oder -löschungen – in Szenarien, in denen solche Operationen regelmäßig anfallen, kann das eine Einschränkung darstellen.
Raus aus der Java-Komfortzone: Datenbank-Trigger
Wenn ihr bereit seid, die Komfortzone der Java-Abstraktionsebenen zu verlassen und die Performanz eurer Auditing-Lösung verbessern wollt oder wenn ihr nach den umfangreichsten Anpassungsmöglichkeiten sucht, könnte triggerbasiertes Auditing die richtige Wahl für euch sein.
Schauen wir uns an, wie wir unser Beispiel in ein triggerbasiertes Auditing-System umwandeln können.
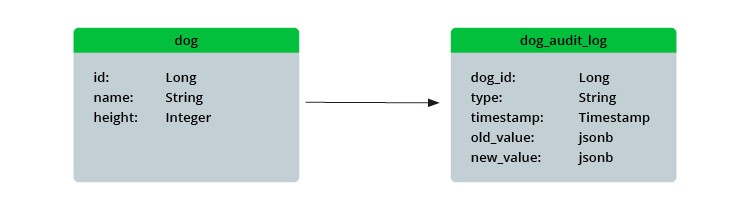
Im ersten Schritt zeichnen wir jede Änderungsart in einer separaten Tabelle dog_audit_log auf, die eine Spalte für new_value und eine für old_value, jeweils vom Typ jsonb, beinhaltet. Wir verwenden jsonb für eine einfache Handhabung und um Anpassungen flexibel zu gestalten. Änderungen in der Struktur der Entität Dog, wie das Hinzufügen oder Entfernen von Spalten, beeinflussen unsere Audit-Log-Tabelle nicht.
Damit wir das erreichen, setzen wir eine Funktion in der PostgreSQL-Datenbank um, die die vorgenommenen Änderungen verarbeitet. Zudem müssen wir einen Trigger einrichten, der diese Funktion aktiviert, sobald eine INSERT-, UPDATE- oder DELETE-Operation durchgeführt wird.
CREATE TRIGGER dog_audit_trigger
AFTER INSERT OR UPDATE OR DELETE ON dog
FOR EACH ROW EXECUTE FUNCTION dog_audit_trigger_func()
Es gibt auch automatisierte Lösungen, die Datenbank-Trigger nutzen, wie zum Beispiel Debezium. Dieses Tool basiert auf Kafka und extrahiert CDC-Events aus dem binären Log der Datenbank.
Um an die Audit-Daten zu kommen, müsst ihr die dog_audit_log-Tabelle „manuell“ abfragen und sie mit der Dog-Tabelle verknüpfen.
Vorteile:
-
Entkoppelte Architektur: Ein Hauptvorteil der triggerbasierten Überwachung ist ihre Unabhängigkeit von der Anwendung. Sie bietet eine nicht-intrusive Auditing-Lösung, die im Hintergrund läuft.
-
Umfassendes Auditing: Diese Methode erfasst alle Änderungen – nicht nur die, die innerhalb der Anwendung erfolgen. Das macht sie ideal, um Daten aus verschiedenen Quellen zu prüfen und sicherzustellen, dass keine Änderungen übersehen werden.
Nachteile:
-
Nicht mit Hibernate gekoppelt: Da die triggerbasierte Überwachung nicht direkt in Hibernate integriert ist, könnte sie für Anwendungen, die stark auf Hibernate für die Datenverwaltung setzen, weniger geeignet sein.
-
Kaskadierende Trigger-Hölle: Seid euch der möglichen Nebenwirkungen bewusst, die durch andere Datenbankoperationen ausgelöste kaskadierende Trigger haben könnten.
-
Herausforderungen beim Abrufen von Metadaten: Das Herausziehen von Metadaten kann schwieriger sein und erfordert womöglich zusätzlichen Aufwand sowie Anpassungen, um die gewünschten Informationen zu erhalten.
Simples Auditing: JPA Data
Um das Auditing einfach zu gestalten, bietet JPA Data eine simple Lösung für grundlegende Audit-Anforderungen. Es ermöglicht uns, den Zeitpunkt der Erstellung oder Änderung einer Entität nachzuverfolgen, und stellt grundlegende Audit-Funktionen bereit. Und das ganz ohne die Komplexität, die mit Hibernate Envers oder Datenbank-Trigger verbunden ist. Dafür können wir eine einfache Annotation nutzen, die von JPA Data zur Verfügung gestellt wird. Zusätzlich ist es notwendig, die Annotation @EnableJpaAuditing in der Konfigurationsklasse zu deklarieren. Werfen wir einen Blick auf unsere Beispiel-Entität Dog:
@Entity
@EntityListeners(AuditingEntityListener.class)
public class Dog {
@Id
private Long id;
private String name;
private Integer height;
@CreatedDate
private Instant createdAt;
@CreatedBy
private String createdBy;
@LastModifiedDate
private Instant modifiedAt;
@LastModifiedBy
private String modifiedBy;
//Getters and setters
}
Indem wir einfach vier weitere Attribute in unsere Entität einfügen, können wir verfolgen, wann und von wem sie erstellt oder geändert wurde. Im Unterschied zu Envers und triggerbasierten Lösungen werden diese Informationen jedoch nicht in einer separaten Tabelle gespeichert und bieten keinen Schnappschuss des vorherigen Zustands. Das bedeutet, JPA Data speichert nicht die Historie der Revisionen einer Entität, sondern lediglich, wann und von wem die aktuelle Version erstellt oder zuletzt bearbeitet wurde.
Obwohl diese Lösung nicht die umfassenden Anpassungsmöglichkeiten von Hibernate bietet, lässt sich der Funktionsumfang durch Anpassungen erweitern oder ändern, beispielsweise durch Modifizieren des verwendeten EntityListener.
Da keine Snapshots einer Entität gespeichert werden, ist es lediglich möglich, das aktuelle Entitätsobjekt abzufragen; einschließlich der Informationen, wann und von wem es zuletzt geändert oder erstellt wurde.
Vorteile:
-
Einfachheit: JPA Data besticht durch seine Einfachheit. Die Einrichtung und Handhabung sind kinderleicht, was es besonders für Projekte mit grundlegenden Audit-Anforderungen attraktiv macht.
-
Leistung: Dank seiner einfachen Beschaffenheit hat JPA Data nur minimale Auswirkungen auf die Performance, sodass die Anwendungsleistung größtenteils unberührt bleibt.
Nachteile:
-
Begrenzte Audit-Möglichkeiten: Obwohl JPA Data für seine Einfachheit geschätzt wird, beschränkt es sich auf elementare Audit-Funktionen.
-
Keine Erfassung von Löschvorgängen: Ein wesentlicher Nachteil von JPA Data ist, dass es keine Löschaktionen aufzeichnet. Das macht es für umfangreichere Audit-Szenarien, in denen die Verfolgung von Löschungen entscheidend ist, weniger geeignet.
Schlussfolgerung
Zusammenfassend hängt die Entscheidung für die passende Auditing-Lösung, wie so oft, von den spezifischen Bedürfnissen und Prioritäten des Projekts ab.
Hibernate Envers punktet mit nahtloser Integration, sodass man tief in der Java-Welt verwurzelt bleibt. Allerdings kann das zu einem erhöhten Leistungsaufwand führen.
Triggerbasiertes Auditing ist optimal, um Änderungen aus verschiedenen Quellen zu erfassen, kann aber in der Einrichtung komplizierter sein und eine enge Anbindung an Hibernate vermissen lassen.
JPA Data ist ideal für gewöhnliche Audit-Anforderungen, in denen Einfachheit und geringe Auswirkungen auf die Performance im Vordergrund stehen. Für fortgeschrittene Auditing-Szenarien könnte es jedoch nicht ausreichen.
